


After the Modern Data Stack: Welcome back, Data platforms
And no, there is no one way to what is next, we have 1000+ of ways.

Data platforms are the next iteration of the Modern Data Stack setups. Let's explore why.

So we are talking a lot about the Modern data stack again.
What is it right now? Is it dead, irrelevant, post, pre-post, cubistic?
Let’s assume that Modern Data Stack is just about data stacks. We don’t care about any artistic movement here.
But we still need to start with some context about the Modern data stack, what made it look modern, what it was before, and what defined it. We need this to look for weaknesses and benefits, preparing us to take the next step.
Luckily I didn’t need a long research and investigation because Matthew Arderne and David Jayatillake wrote excellent posts about the beginnings of the MDS. What was before, and what it changed?

I highly recommend reading his full series (either now or after reading this).
But I summarize his definitions as a baseline here:
Enhanced Productivity and Capability: Using MDS tooling, teams can build and maintain more than they could with legacy systems. The MDS allows for the expression of all necessary transformations, concurrent handling of various workloads, and defining metrics and dimensions for company-wide use.
Rapid Iteration and Delivery: The MDS enhances the ability to iterate and deliver solutions quickly, serving many users and handling complex analytics tasks that would have been challenging with previous technologies.
Cost Efficiency: Despite the potential high costs associated with platforms like Snowflake, it can run cheaper than previous data warehouses and optimization.
Increased Data Utilization Across Roles: The MDS democratizes data access and usage. Engineers, Product Managers, Finance professionals, Marketing teams, and even C-level executives can leverage the power of data, leading to a broader return on investment for businesses.
Flexibility and Scalability: The MDS can adapt to organizations' growing and changing needs. As more people realize the potential of platforms like Snowflake and Looker, they begin to use them more extensively, indicating the scalability and versatility of the MDS.
The evolution
The whole dead, next, better, Blabla discussion is only fueled by marketing. And to be honest, marketing could be better. A version has problems, so I introduce version B as the better version and combine this by defining a new era and being bold and confident. Congratulations.
But data stack has a natural evolution, as in every technology. We introduce a new concept that solves some of our problems, and then different things can happen:

The new solution could solve a more significant problem nicely but cause 1-2 new issues from the start or increase an existing issue. So it is a classic trade-off. One that sometimes can still be valuable if the solved problem is big enough.
Or the solution works well under specific circumstances but gets problematic in others. No-SQL DBs are a good example here.
The new solution may be solved without introducing new problems immediately. This is quite good. These are usually solutions that can generate a bunch of hype. Snowflake and dbt are good examples of that. Both enabled a different way to work with data, which helped new use cases and, in the sum of everything, created new problems.
The whole modern data stack is the second type. The democratization of data impact was vast and essential. It made powerful data setups beyond analytical or other closed systems accessible and affordable for so many more people. It clearly defined and opened up an industry.
And, of course, with all the scaling up and new ideas that have been added and introduced, we see plenty of problems: some small and some business-threatening.
And this is when evolution is happening. Just based on the pure drive of engineers. We see something that is not working, so we build a solution. And in one of 100 times, one solution is so good and well done that it creates an evolutionary step.
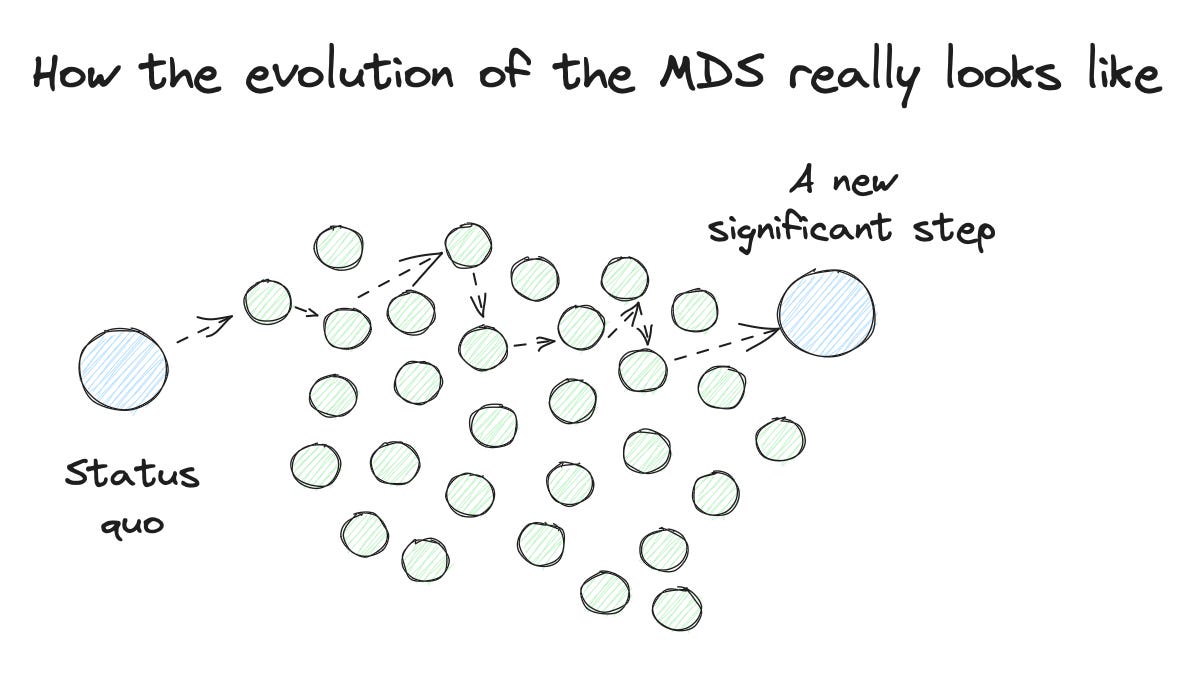
The funny thing about evolution and potentially the one often missed out. Evolution is never linear. It branches out, explores, and creates massive amounts of variants. That is the beauty of it.
But it is also why there is never “the” next. But hundreds of next. And out of them, at some point, we will see a step changing the ways in such a good way that we could declare it as a new paradigm.
We are not there yet. But we can already see the branches, which is exciting.
The problems
Spend a week on Data LinkedIn, and you will get a feeling for the problem of the modern data stack. It creates a lot of engagement to write about pain and issues so that you will see plenty of them. This is good; we must make them visible to create these new iterations.
Let’s pick three core problems:
Missing design or architecture
I guess this should have been the one that was the easiest to predict when the MDS happened. Of course, when you open up a space and make it accessible for many more people, you invite chaos. It’s quite a natural step.
Setups that started small with a little bit of Fivetran and dbt, when scaled up, can grow into maintenance, quality and, finally cost monsters.
The underlying cause for it is missing design principles. And not that they are missing in general. Talk to the folks that have done data modeling for years; they have design principles. And you can see them suffering on LinkedIn a lot by explaining simple things to the new audience.
But it is also wrong that we know and have everything already. The environment has changed and keeps evolving as well. Just take event stream data - most existing data modeling approaches don’t have an answer to how to work with them effectively (how to store them, yes, but that is not the problem).
So design and architecture need to evolve. And potentially in at least two different ways:
We need to take a snapshot of the status quo, explain the landscape in its vast variation, bring it down to foundations again, and then apply common design principles. The data engineering book by Joe Reis and Matt Howley is a great example. It is the most needed book for the current state of data stacks.

We also need to evolve common principles to match new challenges. Just because the circumstances have changed and therefore we have to provide new things. Let’s take my event data example. We can easily store it properly with common principles. But we now have business teams who ask entirely different questions that can’t be answered by classic BI principles anymore. Therefore we need work on Ahmed’s activity schema and the temporal joins to provide a new principle.

Data quality issues all around the place
This might be the fastest issue to appear and become a real problem. Also, because it was always a problem. Before MDS, there were data problems. But they were potentially smaller.
If you scale up systems with minor issues, they usually become big.
So the MDS was not tired of inventing new categories to throw them at the problem. There were times when it looked like there was a new observability, governance, or catalog product launching every day.
But the same with design. Some things could be solved by applying common principles (like tests), but some problems need to take a step back and find solutions closer to the root. All the work around data contracts is such an example of taking an old principle but evolving it to a new situation.

Integration hell
I can still remember one slide I had in a presentation I gave to a board of directors for giving us a budget to build a new data stack: The beauty of best of breed.
No more lock-ins
Fewer costs because we only buy what we need
Always the best solution for every phase
We got the budget immediately - everyone was on honeymoon. They introduced two new stacks over the next five years.
On paper best of the breed still sounds excellent. And you will see raving LinkedIn posts, where people show their cool (primarily open source) data stack. Look how cool I can assemble tools. And I must know it. My first LinkedIn post that went viral was about something I called the Hipster Data stack. People love it mainly because they don’t have to manage it.
My problems with many tools so far:
Constant context switching
This is the invisible one. But it is serious. Imagine you can do all of your work in Excel. Yes, it needs training to get better and faster. But you know that after that you can do everything. That is exceptionally cool because every small new learning immediately benefits all your work.
Now you have to do this for 5-7 products. You need to understand them and keep up since they release new things and change things. And my scariest part (and it is not fun for the people involved) is when a product gets out of business.
It was switching context multiple times a day because introducing something new that needs changes in all the tools costs so much energy.
Play them in sync.
It is more than just an orchestration problem. For this, you can add an orchestration tool (we have tool number 8). It’s much more. Let’s take a simple problem. One of your metrics does not match.
My favorite example is ad spending.
You know how much you pay for it, but your dashboard tells you less. In theory, the problem can be caused across your whole tool stack. Is the issue already when loading it to your lake, when it is ingested in the warehouse, or during the 20 transformations, or is it a BI cache layer problem? You spend days finding it.
With these problems, we see plenty of people and companies working on ways to improve or overcome them. I will now look at a specific evolution thread that is a natural response to what the MDS did in the first place.
Hello, Data Platforms; great to have you back.
While the MDS broke things up and made them accessible and affordable, a natural pendulum movement is to go back and bring some pieces together again.
So, of course, we see this evolution step now getting more attention. But since we are on the evolution track, data platforms today differ from the ones the MDS blows up.
Next-gen data platforms - what makes them different?
Closed but open
Legacy data platforms were often a closed environment. A closed environment has a lot of benefits. The major is simply control.
Control from a technical perspective means you can ensure that no bad things happen since you know what goes into the system and in which way.
Control is also great for data quality since you control all steps for transformation.
And control is excellent for commercial success. Once on the platform, it is hard to move on, so you keep buying these user licenses.
But control means you control the use cases the platform supports. And here we have the biggest problem. Your customers are forced to live with the use cases and the standards you provide them. This might work out great for one team, but for another, it is like running into walls all the time.
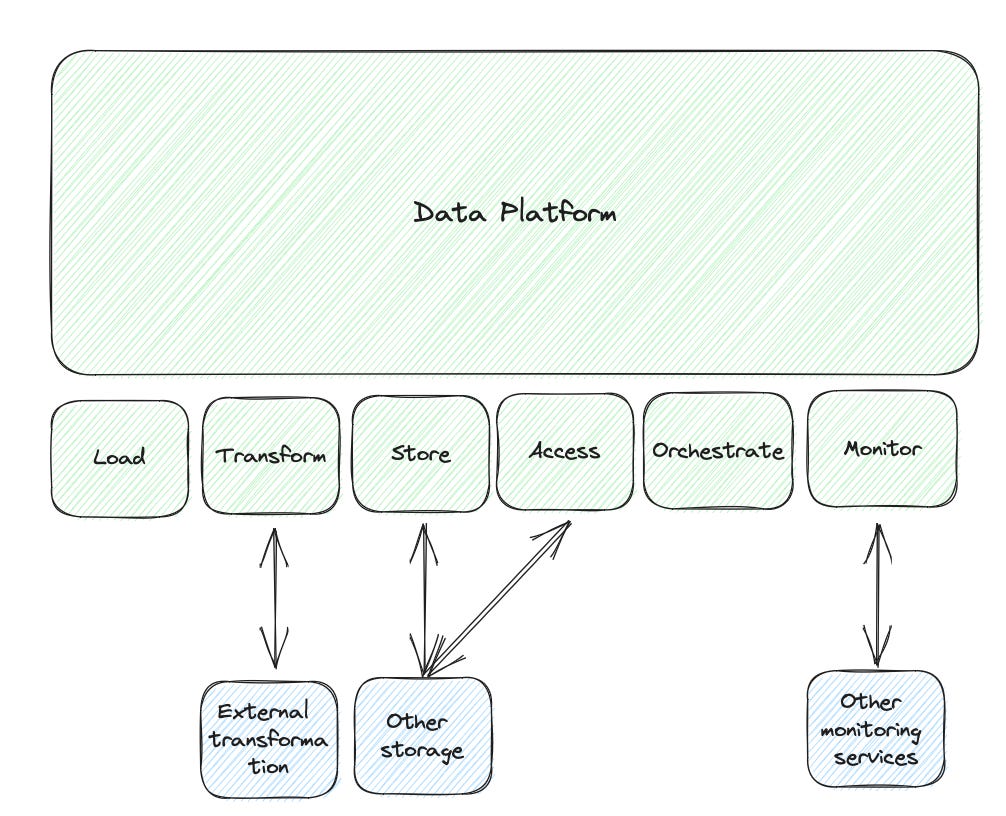
New data platforms still give you control, but more is needed. The control here is mainly on the integration steps or the meta layer. Here they need to control things to give you the platform's benefits.
But they are as open as possible. So that you can integrate other services, sources, and endpoints - the ones you need to enhance your setup.
What does this look like? I will do my examples based on the Keboola platform since I know this one best. But all others (I will list them later) should work similarly.
In Keboola, I can use their provisioned Snowflake instance. This is great because they will handle all the nasty things (at least for a small data team), like permission handling for me.
But I can point Keboola to my existing data storage if I want. Or I can run a hybrid with my existing one and some stuff on the Keboola one. It's a straightforward configuration.
I can add custom transformations in SQL or Python directly in the Keboola platform. But if I want to, I could have my transformation service trigger it from Keboola, access and transform the data, and then pick it up in Keboola again.
Once my data is in the right shape, I can push it everywhere where I like it to be.
So, in the end, whenever I decide to keep things in Keboola, I get a fast and reliable integration as a reward. But if I have something custom, the platform is flexible enough to support that. Sometimes with some additional work on my end. But doable.
The additional person on my team
In football, we mention a 12th person in your team when you play at home and have a massive and loud crowd, like in Liverpool or Dortmund. It gives you additional power.
For me, the new data platforms are just like this. I often work with companies with 1-2 data team members. And they do the complete service from data pipelines to the dashboard factory.
Hiring more people is often not an option. Data people are expensive, and even when you have the budget, they are not sitting in cafes and waiting to get called to the pipeline.
And we all know that you need the experience to solve things quickly and scaleable.
The new data platforms are like an additional hire. This hire doesn’t come for free, but it/she/he can start on Monday and likes to scale like a pro.
I would like to give you my favorite example. Usually, it is a good idea to move data around in incremental updates. You don’t want to load all the data all the time. But the total is not so easy to implement from scratch. You must extend your data with proper columns to help indicate the delta payload.
In all data platforms, incremental load often comes with a checkbox (and a select to select the column that serves as criteria (id or timestamp)). So I can manage the costs and time of the pipeline without extensive experience.
The meta power
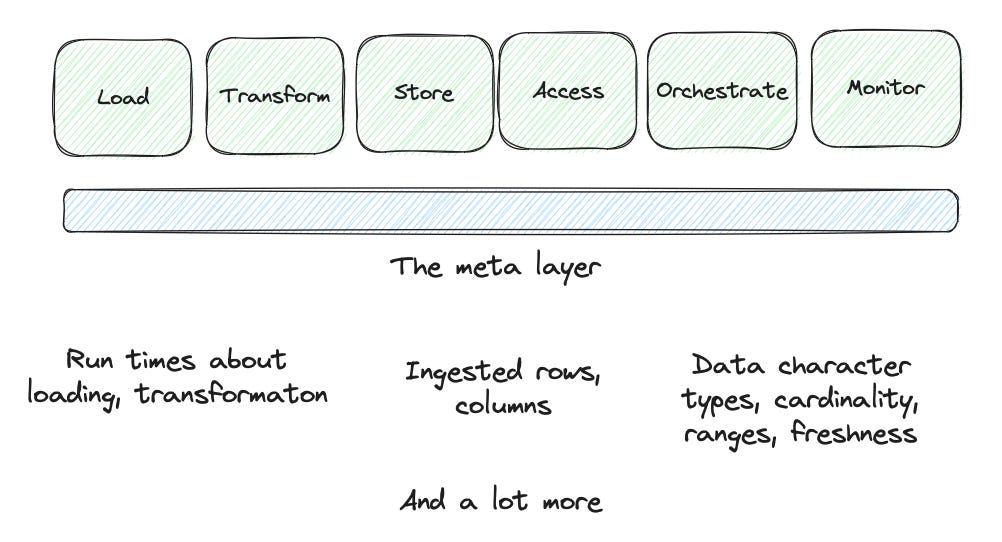
The meta-layer is the secret (or maybe not so secret anymore) missing thing from the modern data stack.
So what is the meta layer?
I do a short definition here since it would require an entire post to cover it in depth.
The data is moved or changed when we do things in a data stack. All these transformations and copies create an invisible chunk of new data - the metadata.
How long did the load take?
How many rows were included? How many new entries (when incremental)
How much CPU runtime was required? How much did it cost?
How has the schema changed?
You can get additional analysis, alerting, and automation based on that.
We have a problem with the breakdown of this chart; the Sydney branch is missing. Oh wait, the cardinality is different after this transformation step. It was solved and deployed in 60m.
For me working with metadata is just getting started. You can’t see it entirely played out yet in the data platforms. But they have the ingredients to go all in on it. Classic MDS tools would have to integrate the metadata from other services (if they can even get them).
So what are these new data platforms?
We see at least three different types at the moment.
Integrated data platforms
These platforms offer integration, transformation, and export in one platform with an integrated orchestration. Just as described above.
They are usually open enough to run parts of your stack outside their platform.
But you get all the benefits we mentioned before.
Vendors:
MDS tools in a box
You can compose your data platform by combing MDS tools like Fivetran, dbt, Preset, and many more.
The benefits are mainly on the admin side of things. You can add new integration with a click (and no talking to sales), get one bill (trust me, this is a significant help), can manage access roles in a central place.
Vendors:
Open source MDS tools in a box
Bring different open-source solutions together, host and maintain them and make the transition between them more manageable.
Vendors:
Summary and looking into the future
After doing “classic” MDS projects, I did two projects using Keboola. Both were for clients with small data teams. We got everything set up quicker and spent less time working on the stack and more by adding new sources or creating new data assets for the other teams. Is it always like that? Most likely not; as always, it comes down to the requirements.
I want to see more things from the metadata to give me cost and resource control and better guardrails before breaking something. I saw some promising demos, but they have yet to be generally available.
Is this the only evolution of the MDS? Of course not; as written, it is one thread. I will cover another thread in my next posts: Native Apps on Cloud Warehouse.
