


Data pipeline orchestrators - the emerging force in the MDS?
The one who controls the flow controls everything


Some weeks ago, I wrote about evolution threads in the Modern Data Stack and pointed out that data platforms are one of these evolutions happening right now. One of my takes is that what makes data platforms so strong is the control of the flow and the data loaded and transformed. And the sheer amount of metadata this produces.

When I posted about it on LinkedIn, Simon Späti rightly commented that you can achieve something similar in an open-source stack by having a powerful orchestrator.
I never thought about orchestrators in that way, but he 100% has a point here.
This is why we look into a different MDS evolution thread today: Data pipeline orchestrators, where they are, and what role they can play in the future. May take is here: it can be the one essential role. But let me explain this a bit longer.
What does an orchestrator do?
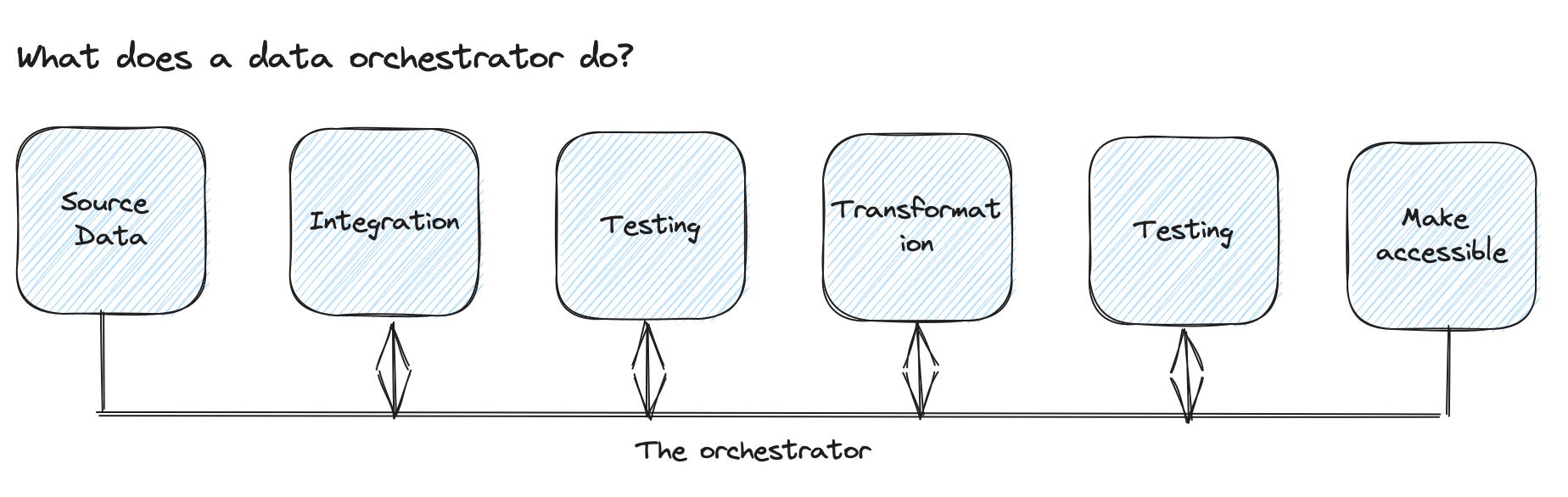
Maybe we can start with "Moving things from left to right." Data pipelines are often multiple copy machines; data gets loaded and then in a multi-transform setup in different copies changes and adapted and, at some point, finally stored.
How much an orchestrator does depends on the orchestrator. The pure orchestrator triggers steps, waits for a response, and, based on the result, initiates the next steps or multiple in parallel. But it does not have any load or transformation logic.
A hybrid orchestrator has some of both; for some steps, you use build-in connectors (like to load specific data from the specific platform), then some transformations can be added to the orchestrator as well as custom code, and for some steps, you trigger an external service.
Some orchestrators need to persist data actively in each step to reuse it; others can "hold" it (well, they persist it, too; you don't need to do it actively).
What combines them all is the value of taking data from a source in a specific shape and load, transforming, and storing it along the way.
Why do we even need to do that? So far, we can't run queries like
Select lead_id, lead_name, lead_score from hubspot left join vertex on hubspot.customer_id = vertex.customer_id- so, we need data pipelines to combine all these datasets and make them work together. And the orchestrator is doing a lot of the heavy lifting or ensuring things are happening.
We mentioned some aspects here already that we will pick up later, but let's look at what a data pipeline orchestrator does in detail.
What does the data pipeline orchestrator do?
Sorry, I take a nice shortcut here. But instead of coming up with some own examples, I pick the ones that the different orchestrators use in their documentation, getting started, or use case videos/posts.
Astronomer:
https://docs.astronomer.io/learn/cloud-ide-tutorial
Build a simple ML pipeline:
Query data from a database
Apply basic transformation
Train a simple ML model
Schedule and control the pipeline versions with Github
Dagster:
https://docs.dagster.io/tutorial

Build a simple load, transform, and store pipeline:
Ingest data
Work with DataFrames
Create a visualization
Store the data
Schedule the pipeline
Connect it to external destinations
Kestra
https://kestra.io/docs/tutorial
"Hello world" flow introducing the basic concepts (namespaces, tasks, parametrization, scheduling, and parallel flows):
working with the inputs and outputs of a task
define triggers in the flow
Add parallelism
dbt
https://docs.getdbt.com/quickstarts/bigquery
Wait, what - dbt, here - yeah - in the end, it is a SQL query orchestrator and a pretty light one, too.
Access data in BigQuery
Run transformations
Materialize the data
Run tests
Add a schedule
Keboola
https://help.keboola.com/tutorial/
Wait, what... All data platforms have orchestrators built-in - Keboola is an example here for the category.
Load data with standard connectors or extractors
Transform the data
Write the data
Send the data to destinations
GCP Workflows
https://cloud.google.com/functions/docs/tutorials/workflows
We can skip the wait what, I think you get the idea.
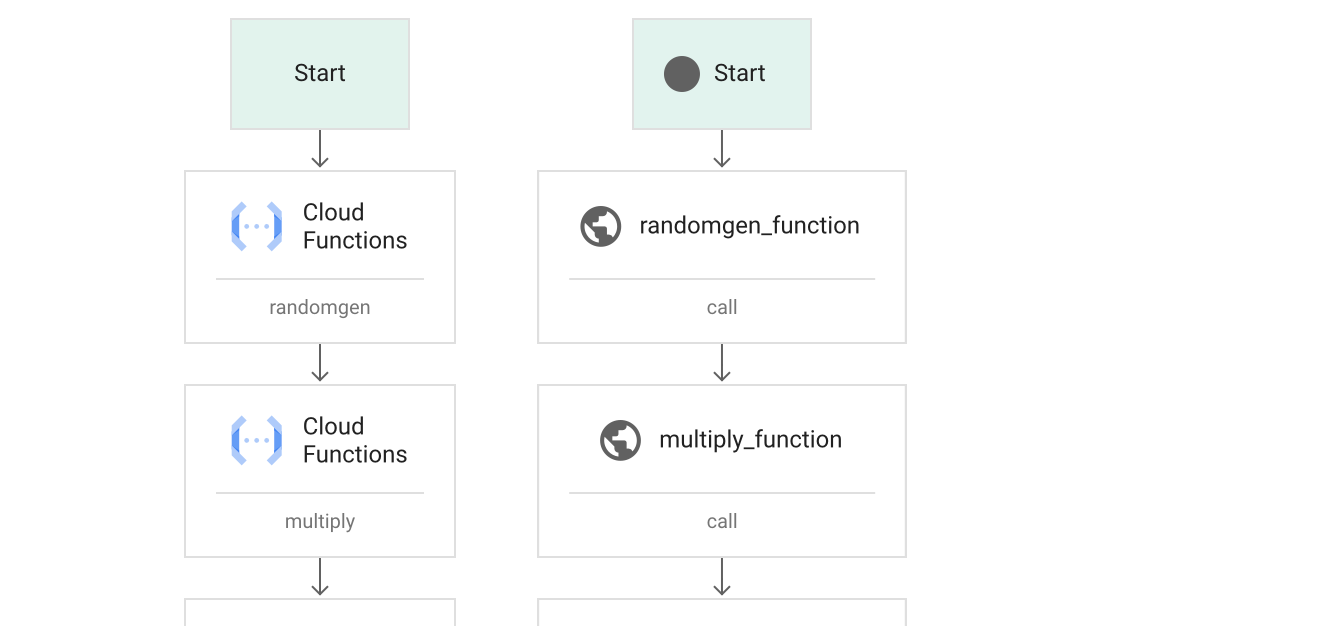
Create custom functions to do the heavy lifting
Use Workflows to trigger the functions
Request data from an external source and use Cloud Run to work with it
Naturally, these are basic examples (I still hope vendors will also put out complex tutorials for the next steps), but you should get the idea. These are good ways to test and learn about the different orchestration approaches by just doing the getting started tutorials (maybe something I might do a video about in the future).
So, these tutorials will already show you that there are differences between the different orchestrators. Let's take them apart more to understand the different approaches and models.
What are the different types of orchestrators?
Compared products:

All placements on the charts are subjective and can be debated by you with a fierce comment.
Pure orchestration to data platform
We span the axis from pure orchestration to data platforms. The significant aspect is much more heavy lifting is possible with the orchestrator. Or how dependent you are on external services.

Pure orchestration
A pure orchestrator is just handling the orchestration part: managing steps, triggering external services, taking the results, handling conditions, and scheduling the whole thing.
You will rarely find any custom code here that is loading or transforming data.
There might be some standard connectors already, but they are limited.
Data Platform
The backbone of a data platform is the orchestration.
But many of the tasks in the pipeline can also be done with the orchestrator. Either by using prebuild components or custom code that the orchestrator executes. External services are just utilized in exceptions. The integration between all tasks is usually deep so Metadata can be used easily between the tasks.
There is a clear tendency in the market to move to data platforms. Not a big surprise, people will ask, what is your tool replacing, and an orchestrator alone is first just an addition. I can replace an ETL tool once I can also handle 90% of data integration. Once I can do the transformation, I will replace the dbt cloud. And so on.
General to Special
The orchestrator can either be built for basically any orchestrator use case, or it is strictly built for a very special case.

General is one tool to rule them all. One tool your team can focus on and no park of different solutions. It can be even that data and application engineering build things on a similar stack, which can be beneficial.
Special gets you the best solution for a special use case. If this use case is dominant, a unique solution can be easily worth the investment.
There are different ways of special. One way is the kind of use case. dbt is an SQL transformation orchestration. This is a very special use case and, therefore, a special orchestrator. GCP Workflows can be used for plenty of use cases, but it is specialized in GCP services (but not limited to them).
By implementation

Opinionated or standardized frontends to code
Opinionated or standardized can be significant. It usually hides a lot of complexity under a specific kind of implementation. This can be a "plug & play" experience as we know it from tools like Fivetran or Segment. Or an opinionated way, like the YML configuration you use with Kestra.
The limitation of standardized is natural customization. Every standardized tool tries to integrate customization at some point, but it is often limited and poorly integrated.
Opinionated needs investment that the approach really pays off. It requires a learning curve to get started and be efficient once you master it. This is the real threshold for me for the opinionated approach. When my investment, in the beginning, is too big and the gains are not clear, I won't invest the time.
Code
Of course, code solutions are also opinionated. Some more, some less. But you can incorporate them into your usual way of building applications. So, getting started with Airflow should be straightforward when you have a good Python understanding.
Code solutions are highly configurable and can usually extend to almost all use cases. When a team is experienced with a specific language and already has a codebase, an orchestrator in the same language can be a natural extension.
Open source to proprietary
There are almost no pure open-source projects. Pure is for me that no paid or managed services are in place as the next upgrade step.

Open source
Interestingly, we find quite a bunch of dominating open-source solutions for orchestrators. Airflow was at least a dominating project in the last few years, and it has generated many follow-ups using the same mode.
All of the ones mentioned also offer a managed or cloud version of their orchestrator.
Proprietary
There are at least two versions of proprietary: platform-based or own-platform.
The platform-based ones are part of a platform offer, like GCP Workflows or AWS Step Functions.
The own platforms are an essential part of a data platform.
Interestingly, no single-purpose orchestrator service is a proprietary paid platform (as far as I know). Maybe something we might see in the future.
The metadata sorcerer
I started with emerging forces - there is a reason why I believe that orchestrators are in an interesting spot in the Modern data stack.
One of the MDS's strongest but weakest points is decoupling things. It enables you to combine just the right tools without big platform lock-ins and bundle prices. On the other hand, the coupling is never easy and often so much work that most tools are isolated.
This is fine as long as you have a small setup. It is no big surprise that most "Hey, I have this cool new data stack" posts or videos show stuff done on a local machine. But what works locally does not automatically work in a shared and scaled environment.
So, orchestrators can be the glue to bring all MDS things together. And in theory, they are doing this job, but interestingly, not always. This might be why most managed orchestrator services are integrating more and more typically decoupled MDS assets to couple and bundle them.
But there might be a source where orchestrators are in the perfect spot and is not utilized to its full extent: Metadata.
Why iMetadatata important - Lindsay and I wrote a post and even did a live show about it. So here is the gist: When we operate a data stack, we apply architecture, design, and implementation. But these things need constant feedback if they still do the job in a way that the data strategy has described. The best feedback system of operations iMetadatata. DevOps makes use of systems and application metadata all the time to identify bottleneck and optimization potentials. In data, the role oMetadatata is currently mainly used for some governance use cases. Even in data observationMetadatata does not have a central role, where most tasks are done by running SQL.
I already described this in a post about data platforms - one huge asset that data platforms have is that they own and control 100% of thMetadatata. This enables them to offer tools to create data setups that can scale under control and handle data quality at each step.
And if you are not on a data platform, the orchestrator becomes your lightweight data platform.
I am extremely curious to see what role metadata plays for orchestrators and if it will become so strong that an orchestrator can use this as their main secret sauce. The interesting step for me is when orchestrators extend their execution metadata by pullinMetadatata from the services they trigger. A central shared log would be a great start.
And when it might be over already
I predict that orchestrators will become the essential tool in the next wave of the modern data stack evolution, similar to data platforms. And I see the generic ones as the strongest forces. And it looks like that open source plays a vital role here.
Is it so, ruling the world for the next ten years?
So far, nothing has ruled the data space for a long time. Cloud warehouses may be the ones with the longest realm. One pattern on the horizon will fundamentally change orchestrators: Streams.
With data streams, we will see many patterns that are currently dominating. This is something for a different post. But an orchestrator for a stream will look differently if it is built natively for a stream.
But until then, keep an eye on orchestrators; if you don't use them, consider them for your stack.
I've also been thinking about orchestrators but I've come to a different conclusion. In my mind the current metadata is so underutilized that once it starts being utilized the orchestration layer becomes much more automated and maybe at some point entirely "disappear" and either get absorbed into the data warehouse layer or the BI layer. You don't need a lot of people writing dbt or creating various metric definitions when those can be derived by looking at the queries that are already running on the data warehouse.
Great post Timo. I have been learning about Mage + dbt, and it seems like a great combination for ingestion, orchestration, and transformation. My main focus in selecting this integration was learning a data stack that can be used with several warehouse options and environments.
This is a substack that talks about this interesting symbiosis:
https://castnetanalytics.substack.com/