

Eventify everything - Data modeling for event data
Eventify everything - Data modeling for event data
An introduction


I started out with data modeling by supporting classic e-commerce marketing use cases. On a high level, this was all pretty straightforward. We usually had one core event - the order. And we build everything around that: sessions and marketing attribution. So we could end up with 1-2 fact tables just for the orders and some more dimension tables.
The tricky things here were two things:
Handle all the different kinds of source data so we can be sure not to limit ourselves in the future (and make sure we cover these slowly changing dimensions)
Make sure we can support all the different kinds of analysis use cases that the analysts were dreaming of
All this ended naturally in quite complex models, which we would translate today in an 80-150 model dbt setup.
We managed it and provided the essential campaign reporting dashboards the marketing teams were eager to get.
All this became much more complicated when I tried to help my dearest friends: the product teams.
The source data for them is significantly different.
You need behavioral data to analyze data for improving user flows and progress, which is event data that can be analyzed in a sequence based on an identifier like a user id.
The same kind of data today is super useful for growth teams and sales teams to understand an account's progress and potential for renewals and upgrades.
But how do I model these? Put them in 40 different fact tables with 40 dimensional tables. No, that does not scale.
It took me years and plenty of conversations to develop an approach to event data modeling, which I can write down.
The approach works really well for me in now five setups, but with all approaches, they live and evolve. This is the 2024 version of it.
The layers of Event Data Modeling
On an abstract level, we can understand the process of data modeling as a journey through different layers. All layers serve a specific purpose (store scalability, apply business logic, enable reporting or application), making a data model easier to grasp and extend.
Rogier Werschkull described his approach to layers in this LinkedIn post, which I have bookmarked and would like to share with other people when they ask.
He breaks it down like this:
Layer 1: Raw source
Layer 2: Read layer
Layer 3: Ensemble-based data modeling - simplifying future data integration
Layer 4: Dimensional modeling - for user-friendly presentation layer
Layer 5: Analytical consumption
These layers show how you go from source data to a consumable version of the data. All layers have their own purpose and potential complexity. They help to modularize your data model.
Therefore, I use a similar layer approach for event data.
Disclaimer: But we already have a data model
First of all, that is excellent. Congratulations - this is a perfect foundation.
Every event data model that I have built so far has always been built on top of the existing model. You can describe it as a plugin, addon, or application. I like the application layer terminology.
It's basically similar to the Layer 5 mentioned above or the presentation layer if you use this term. At this point, the data is finally ready for consumption.
So, when we look at the layers in the next step, understand them as sub-layers of this specific application.
Ultimately, the event data model does not care about the data model you use in general. It works fine on top of each of them. The first important part is where we can find the events.
Therefore, let's move on to our first sub-layer.
Sub-Layer 1: Raw event data
All raw event data are stored in their original form in this layer. The source and approach mostly drive the original form to load the event data into your data stack.
It's optional if you really model this layer out physically. Sometimes, it might be enough to reference the original event source. I like to build it out because it gives me a point of entry and more control over the data. But it comes with additional compute and storage costs (depending on the materialization strategy).
Event pipelines
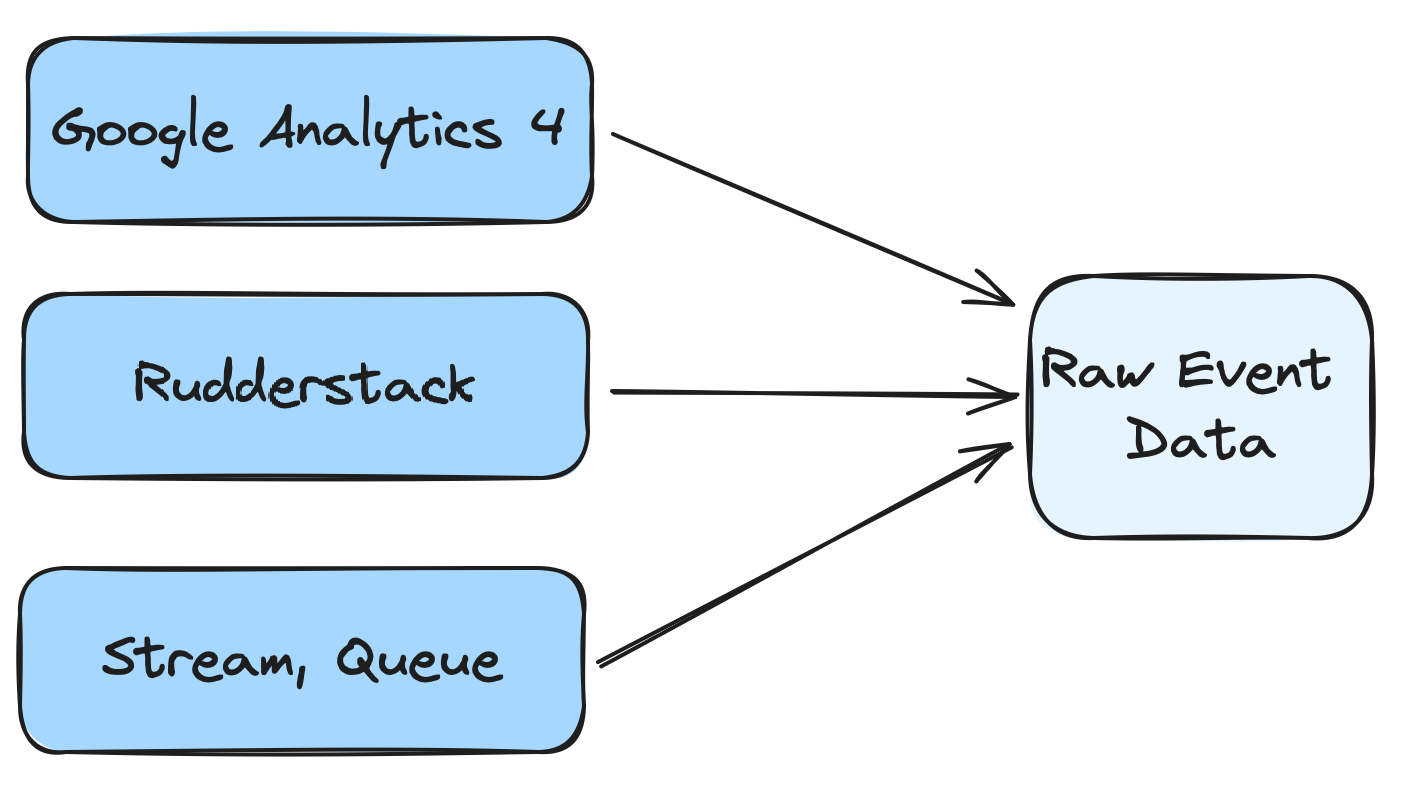
The most common form is data from event pipelines. These can be specific analytical event data pipelines like Snowplow, Segment, Rudderstack, or even Google Analytics 4 (not a recommendation for event data pipelines, but it is often available), and general event pipelines like streams (Kafka,..).
These event data pipelines get events ingested using either SDKs (wrappers around an API) or an API endpoint directly. They are built for high-volume ingestions, transport, and loading into a source system.
Most of these pipelines have qualification steps in between to enrich, filter, or qualify event data before it loads in the source system.
They also take care of the loading itself, and here, it is mostly about schema changes. Schema changes in event data are pretty common since you often extend the tracked context and, therefore, change the schema. But when you use the out-of-the-box pipelines, you are covered.
They all solve schema evolution in different ways. One approach is reducing complexity by loading each event type in one table (Segment or Rudderstack). Or by using a powerful schema evolution process and defined schemas (Snowplow). Or by living an engineer's wet dream and showing off by using proprietary database functions like nesting (Google Analytics).
Eventification

Now it is getting interesting.
We put on our Indiana Jones hats and go hunting for event artifacts in the different various tables.
Here is what we are looking for:
Timestamps
Unique identifiers
Let's pick a schema of some Fivetran data that is loaded in our Warehouse. We can use the Hubspot one since this is often our marketing team’s favorite- here is the marketing data model:
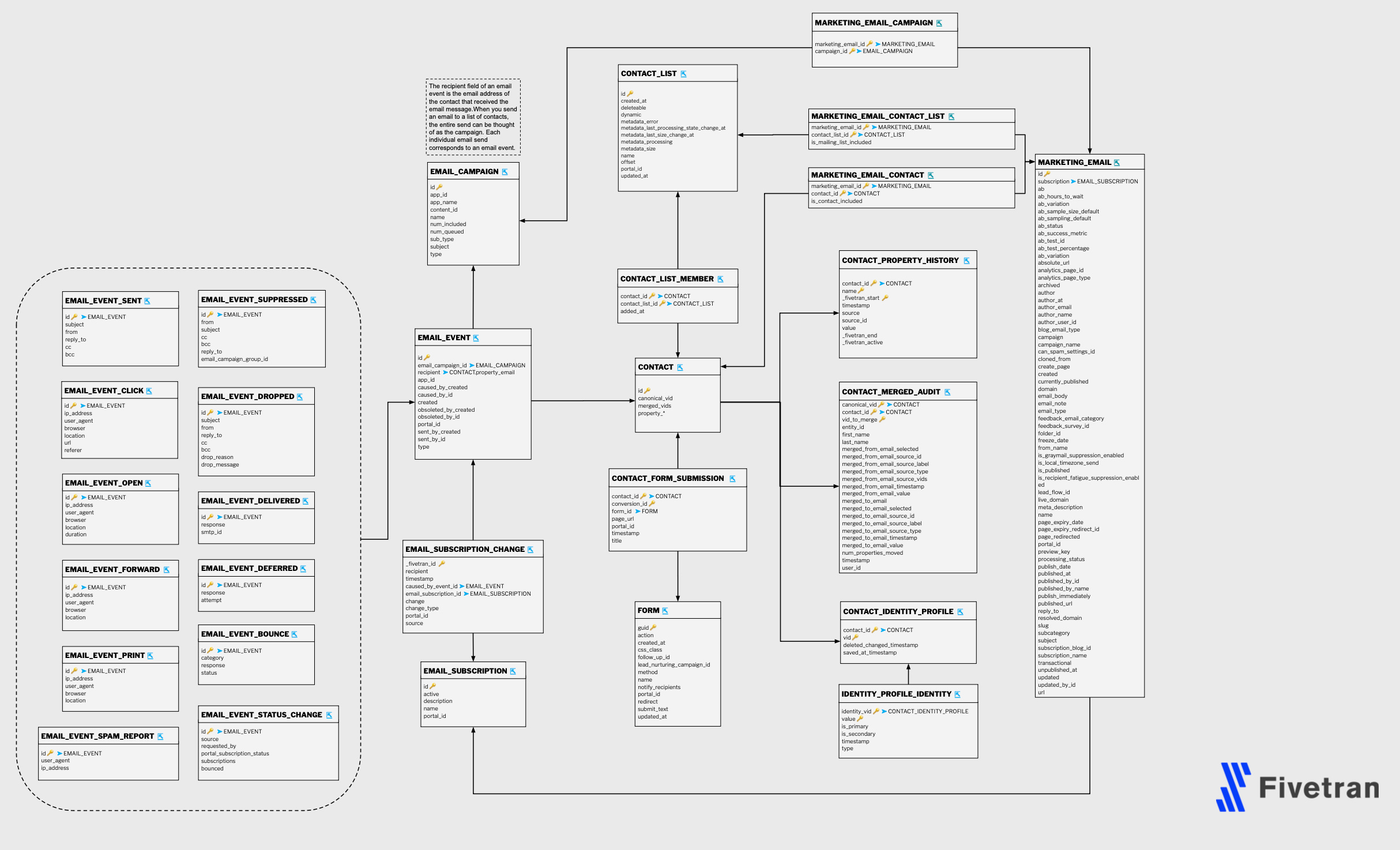
Contact would be an interesting dataset for us since we can construct events like "contact created". The contact table does not have a created_at field (which would be our usual candidate). But Fivetran is giving us a history table. History tables are a great source for derived event data.
In the contact_property_history table, we can look for the first instance for the contact_id and can use this as the "contact created" event.
It is also worth scanning through the history table to check for specific property changes that could indicate other events.
The email event table otherwise makes it easier for us to derive events directly.
One important exercise - you need to make sure to find the best identifier. From the Hubspot model, it is most likely the contact_id, but when we want to join this data with other data (behavioral data, for example), we need an id that is present in both sources. It is usually a good practice to add an account_id or user_id to Hubspot as well. You should use this id as the unique identifier if you have done that.
When we look at the Sales & CRM Model:

The Deals table is definitely interesting. It can be mapped back to a contact. And give us insights into the contact and deal journey. We again have the deal property history table, which can give us insights into the "deal created" event and potential other candidates.
But Deal_Pipeline_Stages is even more interesting since we can get the defined pipeline steps and model the stages from there. How to work with this table is described in the Fivetran Hubspot Documentation: https://fivetran.com/docs/applications/hubspot#dealstagecalculations
With some initial work, we can already surface: "contact created," "deal created," and "deal phase finished" with a unique identifier and valuable properties (like deal_value) as new events.
Again, this kind of work is like a treasure hunt; I have to say, this is usually the part of the project I enjoy most. To get event data without implementation is still pure joy.
Webhooks
Another often overlooked way is to consume webhooks. Any webhook request, by definition, is already an event, and most 3rd tools support webhooks, often for a wide range of activities.
For receiving and storing webhook data, you often need a very simple service that receives any event and writes it to your data warehouse. For example, I am using a very simple Flask app that runs on Cloud Run, and I am using dlt to free me up from all these nasty schema changes.
With these three ways, you can already surface plenty of essential events and activities that define user and customer journeys. The best thing about it is that all these events are of a better quality than any that comes from any frontend SDK.
As written before, you can introduce a physical layer where you bring all these different events together in one place and then go to the next sub-layer. Or you simply reference the origin from the next sub-layer. I prefer the first option, but pick the second one if you get headaches about computing or storage costs.
Sub-Layer 2: Qualify events to activities
This layer is not necessary, but it can help a lot. The layer aims to decide which events will be prepared for later use. This can be a simple selection of events or just renaming, but it can also include more complex operations like filtering, merging, rule-based selection, or calculations of events.
With these operations, this layer can be very important for your setup. Here, you can ensure you deliver a superb data user experience. By ensuring that naming conventions are used, bad data is filtered out, and too granular events are merged or held back, you can design the later data user experience before the data goes into analytics tools like Mixpanel or Amplitude.
I like to call the events after the qualification activities to make a clear separation between both of them. I like to use the analogy of iron and steel. Both have the same core material, but steel has been enhanced for later usage.
You can use different approaches to achieve that, but I like to use the ActivitySchema model for this since it has a very clear and simple structure. Since I use it for all setups, it is very easy for me to work in these different setups since all things are in the same place and happening in the same way.
As an example:
From a webhook, I might get a "contact update" event, and when I check the status, I can see if a contact has been created. Therefore, I can now add this in this layer by renaming the event to "contact created" and adding a where statement "where status = 'create’" By that, I make the event easier to understand and to work with, and I make an intentional decision that I want to use this event as an activity.

In my setups, I define all activities by hand using this approach. This can become a tiring job. But this is intentional. I want to avoid to make it too easy. From my experience, you decrease the adoption rate significantly when introducing too many unique activities for people to work with in analytics tools.
People who use the tool two times a month and then need to scroll through 100 events to find the right one for their analysis job are scared away by the effort it takes. I want to keep it simple for them. And when I define all activities explicitly, then, I make sure that I keep it simple.
Sub-Layer 3: Make the event data accessible for your use cases
My major use case is to analyze the event data in event analytics tools like Mixpanel or Amplitude or in nerdy tools like Motif Analytics.
I have not worked so much with ML use cases based on event data. Therefore, I don't cover them here, but I might do a special post about them in the future.
For event analytics tools, you now have two ways how the data can get into their systems. The classic way is to sync the data up to the tools. You don't need reverse ETL for that. Both Mixpanel and Amplitude support this sync from their systems now. You point them to the right tables (Mixpanel's case) or write a query to define the table and the data (Amplitude's case). Both syncs work really well.
But you have a problem with changes to historical data.
One of the big benefits of the DWH event data approach is that we model the data and, therefore, can also make changes to historical events. Maybe we can enrich a specific event with new source data and introduce a new property. It would be great to have it also for all historical data. But this does not work with the classic sync modes.
One workaround is to use one table for each event type. Like Segment and Rudderstack are doing it when ingesting the data. With that, you can at least add new historical events since you add them to your sync. But it will not work with new properties for all historic events.
Luckily, the tech is moving forward. Mixpanel has introduced their new Mirror product, which does a kind of change data capture on top of your data and, therefore, can handle all the cases where you change things historically. I have not tested it yet since it works fine for Snowflake but not for BigQuery yet, and my current prod event data model is in BigQuery.
On the other hand, Amplitude has a native connection, connecting directly to your Snowflake instance, sending the query down to the warehouse, and working with the result data. I saw one demo, and the speed and UX were still good (even when it was a bit slower). But with that, you have a guarantee that it always works on the latest data version. This approach is quite similar to that of newcomers like Netspring, Kubit, or Mitzu.
Working with the layers
Working with these layers is quite straightforward.
Sourcing new events
Your product and business are evolving. Often quite fast.
There is a new feature just deployed, and we want to see how the performance of the feature is developing.
There is a new integrated tool that takes care of specific onboarding steps. These events would be great.
The last analysis surfaced some interesting drop-off patterns, but we are missing two property criteria, which can be loaded from one of our application tables.
Adding new activities
The new feature is about to be deployed, and we loaded the new events for it from our application database (we used the table where all items are added); now, we can transform these raw items into proper new activities so that the product team gets their release dashboards.
Adding new properties
The new properties for our existing onboarding events are now available. We can now enhance the existing events with these new properties to enable our users to enhance their analysis.
Removing activities
Our latest survey and data usage analysis showed us three activities that don't make sense in their current form. Therefore, they will be replaced and transformed into new activities. We adapt the model with the changes and ensure the old activities are dropped from the analytics tools.
Add new use cases
The sales team is extremely curious to see which accounts did five defined core activities in the last 30 days, so they have a better view when making calls. Therefore, we add a new table to the application layer to have these activities ready and sync them to our CRM.
Final words
From my experience, a data model for event data is much easier to manage than an extended model for other business data.
In the past, the analytics use cases were just harder to handle. Writing custom funnel analysis SQL takes time and experience and therefore excludes many people. This is now changing with DWH integration to event analytics tools. Therefore, a data model for event data becomes valuable.
In most cases, the data model for event data is an extension of the existing model. It does not replace it. Unless you have no data model in place, you can use the approach described here to enable a data model for your event data quite straightforwardly.

thanks for sharing this super helpful...random quick question what do you use for your fun little graphics haha