


How to measure a data platform?
Product analytics for data products

I have to be honest. You can easily trigger me.
Just write something: "How would you measure a [add your business model] from a product perspective?" - this immediately sets my brain in motion, and I usually can't stop it. It starts to think about metrics, potential north stars, and core activities. It creates graphs; it creates schemas. It is unstoppable. So don't trigger me (or please do).
Richa Verma did not trigger me directly or intentionally, but she wrote a really good piece about how to do Product analytics for a data platform.

She had my attention immediately. And her post shows a good way to measure a data platform from a technical perspective. There are a bunch of things you can take away.
But it left me wondering - what would it look like from a classic product perspective focusing more on the user and business value?
And here, my brain kicked in.
I read the post while waiting for our flight at the airport with my family. We had a 90m wait time, and obviously, there was not much to do. The kids were busy with kids’ things, so I had some headspace to let my head wander around to see how I would approach this question.
The first thing that came up was what a metric tree or map would look like.
The metric tree for a data platform
Data platforms have slightly different business models. But we often see consumption-based pricing, usually based on the job runtimes, and subscription-based pricing, which could include several free run seconds. Quite frequently, they are even combined.
Even when you offer a consumption-based model, tracking a free subscription, aka active account, can also make sense since it is a good baseline for account engagement.
I don't explicitly handle free job runs in my initial metric tree. Offering free runs or seconds for runs before you get charged is pretty common. As a first implementation, I would cover the free tier as dimensional values. So, a job executed can have a billable dimension to indicate if it was billable or free. But a v2 could also explicitly map the free-run metrics.
Let's break it down.
I decided on Total Revenue / Month as the primary output metric. It is monetary and indicates how the business is developing over time. We could extend that in the next version to introduce a profit metric by incorporating costs (platform, marketing, sales costs). But we want to start simple.

We go into two tracks from the total revenue, one for the compute (consumption) and the second for the subscription. Revenue from both defines the total revenue.
Let's look at the compute first since published metric trees often do not cover this.
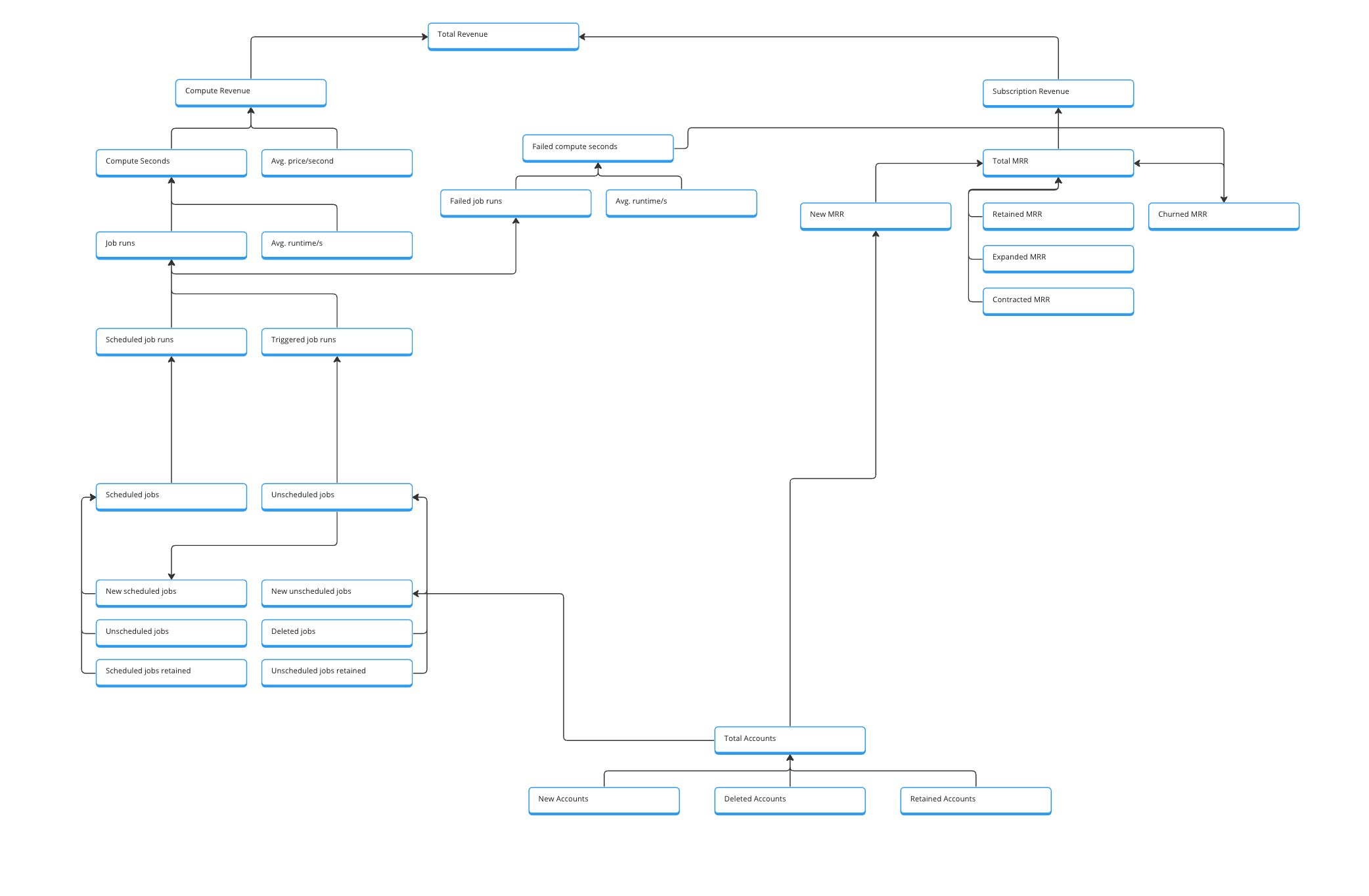
The computed revenue is built up by the computed seconds and the average price per second. The avg. price per second will be calculated by the total compute revenue divided by the total compute seconds in this month. The revenue for each compute run can be added as a dimensional value and then used for sum aggregation.
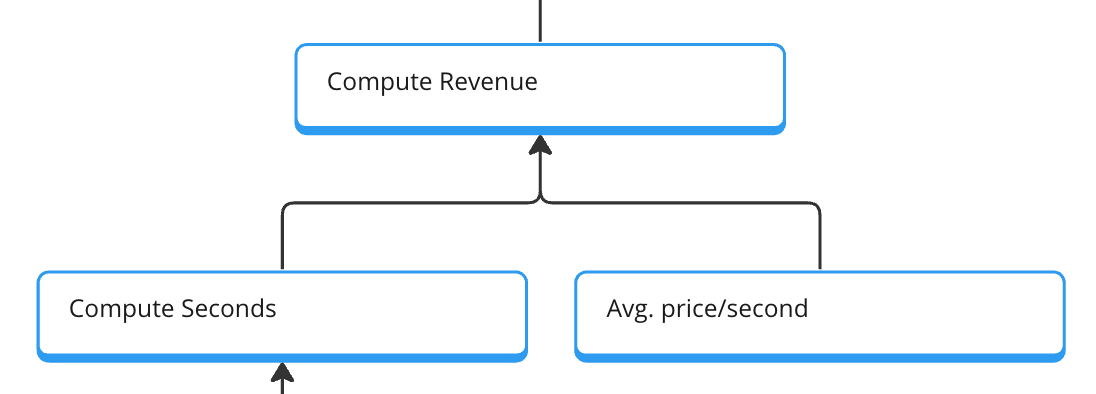
The total computed seconds is calculated by the total job runs and the average seconds per run. As before, the avg. seconds will be calculated by dividing the total seconds by the number of runs and the seconds provided as a dimension to each run.

On the next level, we look at scheduled and triggered job runs. This is already a dimensional breakdown. We could also offer this as a filter option in our BI tool. But I like to break it out here already since this information is helpful for product and customer success to enable more scheduled runs, which have a more positive impact on the computed seconds and are also a good indicator for a received value and trust in the platform.

Below, we look at the job development during this month. And again, we are explicit about scheduled and unscheduled here as well. Scheduled jobs are something we are aiming for.
The pattern here should be familiar to you when you have worked with subscription metrics. We want to show how the total at the end of the month came to be. So we check how many new scheduled jobs have been created, how many have been unscheduled, and how many have been deleted, and we look at the retained scheduled jobs, the ones that we had at the start of the month and kept them.

Additionally, we can do the same for unscheduled jobs. This depends on the amount of them. If they are just a side-aspect I would not add this break-down now.
At the bottom of the first version, we have the account block. Here, we check for new, churned, and retained accounts. This is the essential baseline for our tree, from which we could also go deeper by linking marketing metrics to generate new accounts.

The subscription part is quite familiar; the details depend on the subscription model. We have the classic MRR bridge with total MRR as output metrics. Then, new MRR, expansion MRR, contraction MRR, retained MRR, and churned MRR are related metrics. These are then connected to the account metrics since we need an account to create a subscription.
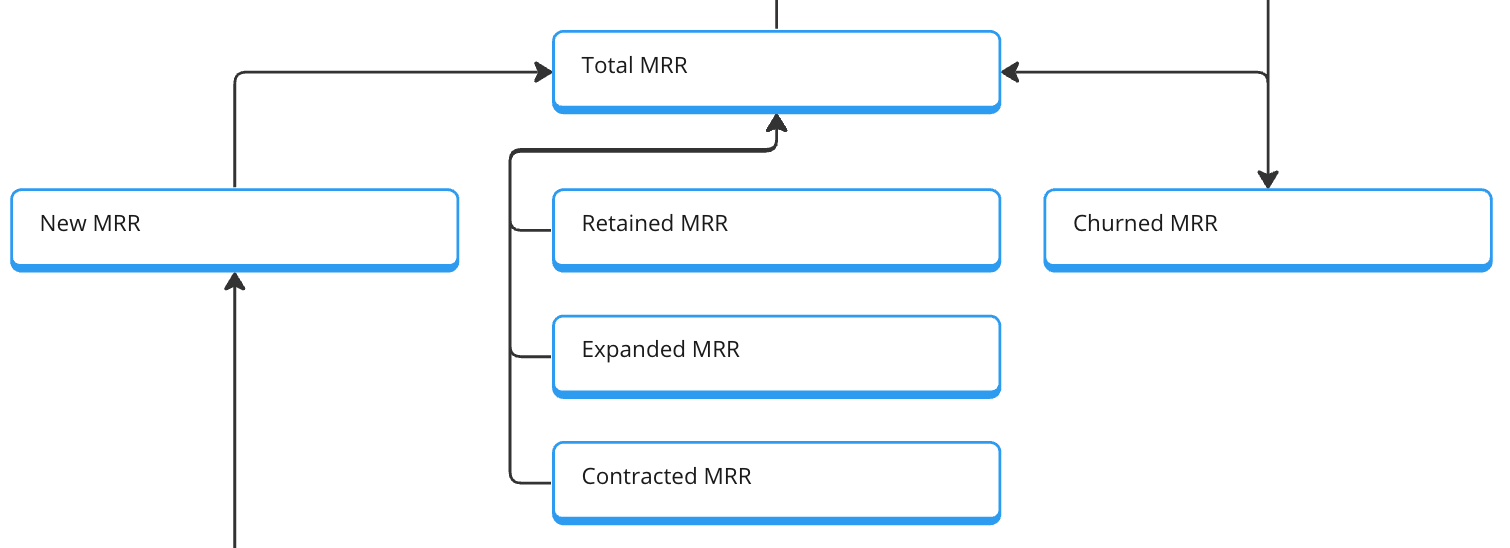
As written before, this is a v1. This tree or graph can quickly expand to include the specific work of all the different teams, such as marketing, customer success, development, and product.
But this early version already enables us to understand our revenue mechanics better. It especially gives us a view into the compute part which is (most likely) the main driver of our growth. Getting as many details here as possible is important since it is also a tricky growth driver. Indeed, the more compute people use on our platform, the more revenue we make.
But we also increase the incentive for cost savings. At a specific threshold, people will become cost-aware since our platform might now be one of the most significant cost items in their budget. The product team's job is to ensure optimization functions are in place to manage costs. Therefore, we must develop metric indicators informing us about these risks.
The first simple step is the block about failed compute seconds based on failed jobs and the average seconds. This is an excellent first indicator of an area where our product does not provide value. Not because of us but as a good way for us to intervene and support from the product side (for example, pausing failed jobs after the X run).
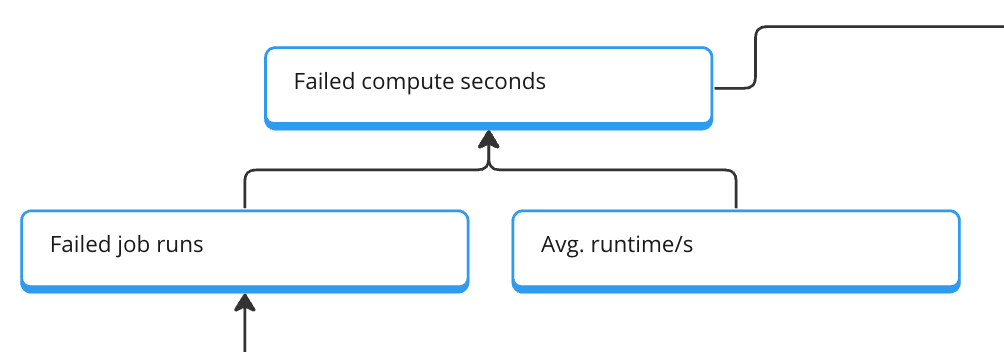
This first metric tree gives us a good setup to include more data in our decision-making. But before we can do this, we need to get the data for the metrics.
In the next version (v1.2), I would definitely add the cost information. The costs of job runs and, therefore, the margin are the main output metrics.
From metrics to activities
There are naturally different ways to get data for metrics. The classic way would be searching source tables or existing metrics tables for metrics covered already.
But I like to show an alternative way here. Not a big surprise to you if you have read other posts by me; I will do this by using event data. We will pick each metric and break down which entity + activity = event we would need to measure the metric and also look a tiny bit into which properties, aka dimensions, could also be helpful for us.
Let's start at the bottom:
Account metrics
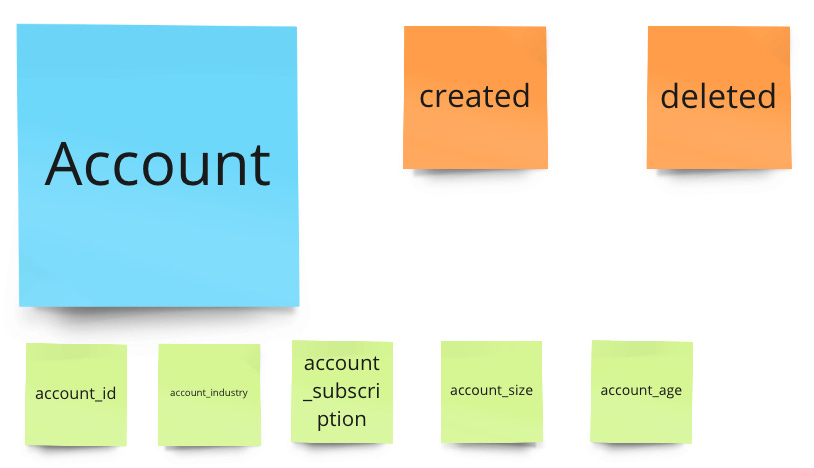
For the account metrics, we need "account created" to get new accounts and "account deleted" to get churned accounts (even when we might come up with a different definition of churned - so we might inactivate accounts after inactivity). Retained accounts are calculated based on total new - total deleted accounts compared to the period before.
We should add good properties, like industry, account_size (number of jobs), and account_age.
Job metrics
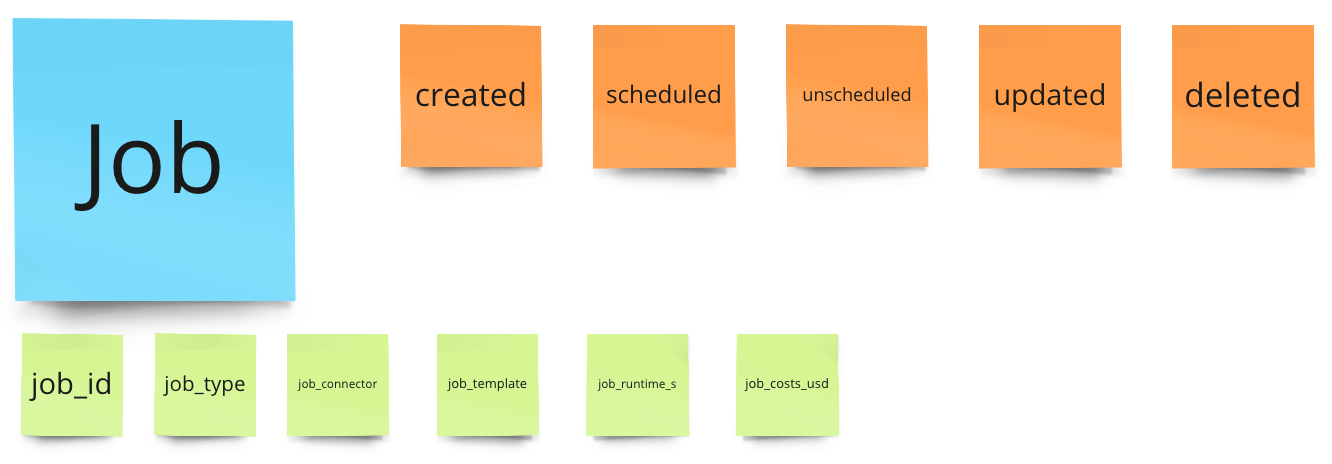
We need "job created" for new jobs and "job deleted". Additionally, we need "job scheduled" and "job unscheduled"—the retained metric we can calculate based on these.
Now we need "job started", "job finished" and "job failed". We could also have just "job finished" and handled success and failure in the properties, but since it is so important to us, I want to have failed as a separate activity.
As properties, we need job type (especially when you have different jobs, like loading, transforming, and storing) and potentially more details. So, if you have connectors, we would add job_connector.
But the most crucial property is job_runtime, which we need to calculate the seconds used. And we also need the costs of a job for our clients -> job_costs. This might be something that we enrich later since these calculations are often batch jobs (to incorporate these crazy discounts that sales teams love to negotiate). To enable a later enrichment, we need "job_id".
Subscription metrics
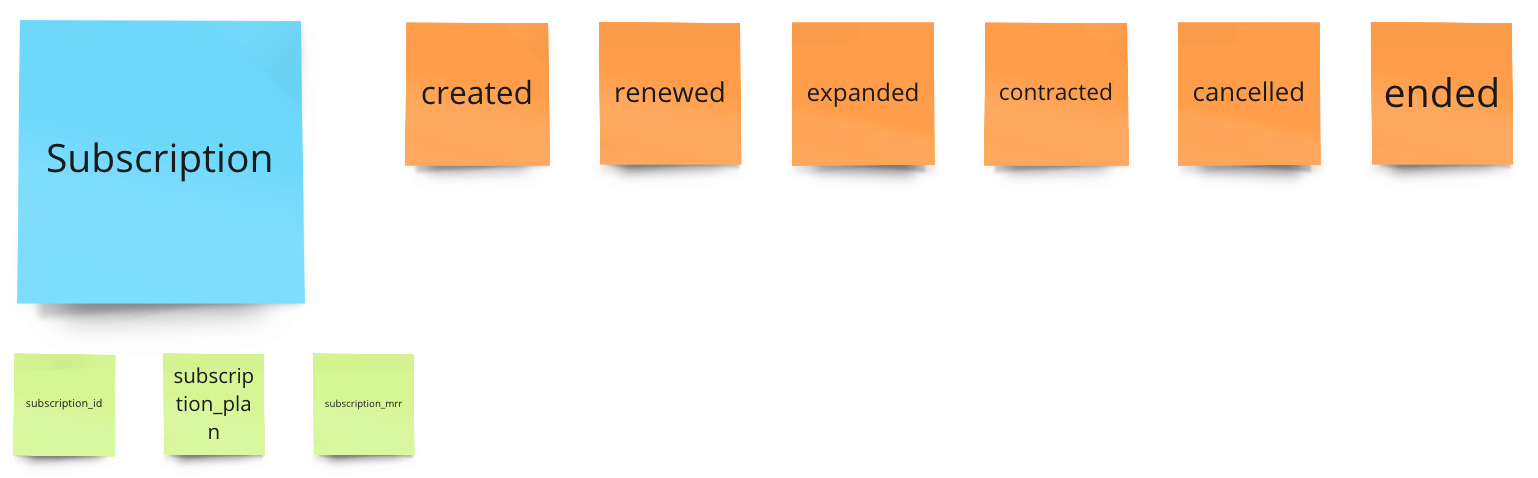
We need "subscription created", "subscription renewed", "subscription cancelled", "subscription expanded", "subscription contracted" and "subscription ended".
With these, we can calculate all MRR metrics.
But to get the MRR, we need at least a subscription_mrr property. This might be similar to the job costs, that this information is not present when you send the event. So you can enrich it later.
But do you recognize something - we just defined only 15 events we need to implement. That sounds doable. With this, we can calculate all the metrics we have defined before. We can quickly get from no metric tree to a v1 metric tree in 1-2 weeks.
Analyzing customer lifetime
The metrics are great for seeing how our business is developing and where our current growth is blocked, and we need new initiatives to unlock growth.
But I would like to add an additional layer (which, in the end, can also get a part of the metrics layer). But the angle is slightly different.
We are looking at the customer journey. And such a journey, when we are honest, is never linear like a funnel. It's a journey where customers can be in specific states or translated to analytics in particular segments. They can move out of these segments after some time, so they often switch their state during their journeys. And they can be even in multiple states at the same time (like "have a subscription" and "power account").
Here are some initial states:
Account created (last 30 days) - the state that kicks everything off and is our new accounts baseline (it is a dynamic window, so it can match with the "new account" metric when we look at the static window of one month).
First Job created (7 days after account creation) - we assume that a new account will add a first job when we do a good job. So we want to move people from Account created > First Job created and measure the success for this (something that can then go to the metrics tree)
First Job scheduled (14 days after account creation) - it might take a bit longer for an account to have a successful job and then schedule it to run constantly.

Have 5+ scheduled jobs running successfully (for l30d) - this can already become our "returning value" state. People who successfully run many scheduled jobs get value from the platform.
Did not add new jobs (last 30 days) - an interesting segment, especially for customer success communication. This might be totally normal (people are just happy with what they have), but it can also be an indicator that they lost interest or track.
Unscheduled 30% of their scheduled jobs (l30d) - also very interesting for customer success. Again, this can be normal but an indicator of a churn process.

What about measuring features?
Feature analytics is extremely powerful and an essential step for product work.
But we already have a really good set of events that describes the features well. And they are pretty high-level, which is the best way to start with feature definition (instead of being too granular).
Let's look at jobs. This is pretty high-level since, depending on the platform, a job can be extracting and loading source data, transforming, and reverse-loading it. It might be tempting to define each of these as separate features. But as a first step, we can use Job here since, in the end, all of them will define a job.
For the job, we already have all the essential events to define a typical job lifetime.
The account and subscription are the same.
More important is that the product team looks at feature improvements from a data angle. So, let's take an example. The product team may work on ten new connectors to extract and load data. They interviewed and surveyed the users; these ten sources were the most requested.
With the roll-out, the product team has to decide how they can see an improvement with the feature improvement. The obvious would be new jobs with these connectors (the connector would be a property value and can be used as a dimension for filtering), scheduled jobs, and computed seconds with these connectors. All this is already covered with the existing events and metrics. So, the new connectors can be rolled out without new events and metrics.
It might be that a new feature improvement will surface metrics and events that are missing. Then, it is a good time to review and extend the existing setup.
The described product analytics setup is powerful and relatively easy to implement. We need 15 events we track, which can be sourced from existing backend jobs or queues.
Therefore, we can have a good setup in 2-3 weeks and a baseline with the metrics tree for planning and reviewing initiatives.
We also get the first set of valuable segments that the growth and customer success teams can use to run targeted communications.
Feel free to let me know if you have any questions or things you think I missed.

Great breakdown Timo!