


The extensive guide for Server-Side Tracking
Take control where you create your event data


I would love to learn if more people had a server-side awakening event.
Mine was over six years. It was not my first time sending events from a backend, and I did this in projects before, mostly sending refund events to Google Analytics. But this time, it was a paradigm shift and a good example of why developers should always play a core and active role in any tracking project.
The project was to implement a new tracking setup for a product with four different platforms (web, iOS, Android, Windows - yes, that was a thing), and a Windows desktop app was in development.
Because of that, the development team was not extremely happy about the implementation, but they indeed wanted the data. We were planning to implement Mixpanel on all of these frontends. As usual, we started with an agnostic design since the events were similar across all platforms.
And when we talked about the implementation, we immediately dived into how the different developers can add the tracking SDKs to the platform they support.
When one developer had a question: "Is there an SDK we can use in our Python application" -
I said, yes, there is one. "Why do you ask? Do you have specific events only accessible in the backend?".
"No, I was thinking about something else. We have a central API serving all platforms, and most actions need an API call."
"Would it be possible to implement the tracking in the API layer using the Mixpanel Python SDK - then we could get 90% of all events covered and implement them just once."
This was my server-side moment. I always had the tools before me but was missing the essential concept. Server-side before was just an extension of frontend tracking for special events. But I never thought about it as the leading setup.
And the implementation of the project worked well. There were specific things we had to test and refine (we will get to that later). But in general, the implementation time was naturally much faster, and the data quality was significantly better (also not a big surprise).
From then on, I would do all setups on the server side. Unfortunately not. Why is that? Let's have a look.
Why don't we use server-side tracking in all projects?
There are different reasons for that. Some are obvious, some not so much, and we start with a not-obvious one.
Tracking designs are done by clicking through the app.
Most tracking plans are defined and created by opening up the application or website you want to track and describing all the core actions happening in that frontend user journey.
This will end up in a tracking plan very close to the frontend application; therefore, the tracking implementation will be too.
My approach is different. I create the first tracking design by ignoring the application at all. We define the typical user journeys from how they can start (some models have different ways), then cover the essential value or aha moments and core functions of the app until the monetization.
By that, we have an agnostic tracking design. This enables us to make implementation decisions after we have made the design and are not too close to the frontend implementation. And we most likely will have discovered important events but not visible on the front end.
Development is not really involved in the process.
Unfortunately, in most tracking projects, the tracking plan is created in Product, Marketing, or Growth teams and then put into a ticket and thrown over the fence by the development team. Usually, without any context, the tracking plan and a link to the docs - that is it. So development teams then implement it quickly, add the frontend SDK and are done.
The development team will be responsible for the implementation approach when you involve the development team from the first meeting and work together to define the goals you want to achieve with the tracking. Interestingly, in these setups, we usually end up with server-side implementation.
The architecture is not built for it.
Some architectures make server-side tracking a no-brainer since you have a central place to add the tracking. But not every setup is like that. When your applications are severed from very different systems, orchestrating a server-side approach might be much more complicated.
It can still be an option to see if at least 50-60% can be done via server-side tracking and the rest via the front end.
I hope these three reasons make sense to you. There might be more, but these are the ones I usually encounter. But I did one trick so far, and I was writing everything in a way that server-side tracking is superior to frontend tracking. Let's have a look to see if that is really the case.
Why server-side tracking is the better option
The limits of frontend tracking
In the classic analytics setup, tracking was initially implemented in the front end (not totally true - there was log file analysis first, but let's not go back there).
There are multiple reasons for that:
- In an anonymous environment, you get plenty of user context for free since the tracking is running on their systems
- It's much easier to develop just one tracking SDK in Javascript. Backends can be in plenty of languages.
- Old types of architecture made it easier to get the data where it is rendered and send it off to the analytics endpoints
But the browser or the mobile device always had and have their problems. Most of all, you don't control them.
The browser is running on the client's system. In this case, you depend on two players: the browser vendor and the user using the browser. The first one has the most influence and will always be in a browser vendor's interest to control tracking. Some have the policy to allow as much tracking as possible, and some counter that with the opposite. The user can control it by explicitly blocking tracking, but this requires some degree of knowledge.
It is the operating system vendor for mobile devices since the systems work more tightly together. If one vendor sees privacy as a core asset in their offer, tracking will be restricted.
And then it is the usage itself. Especially browsers are not built for 100% tracked events. You can't use a database to batch events as you do on a mobile device and make a guaranteed call to the tracking service. And the tracking service can't return an error when there are issues since the front end can't handle it.
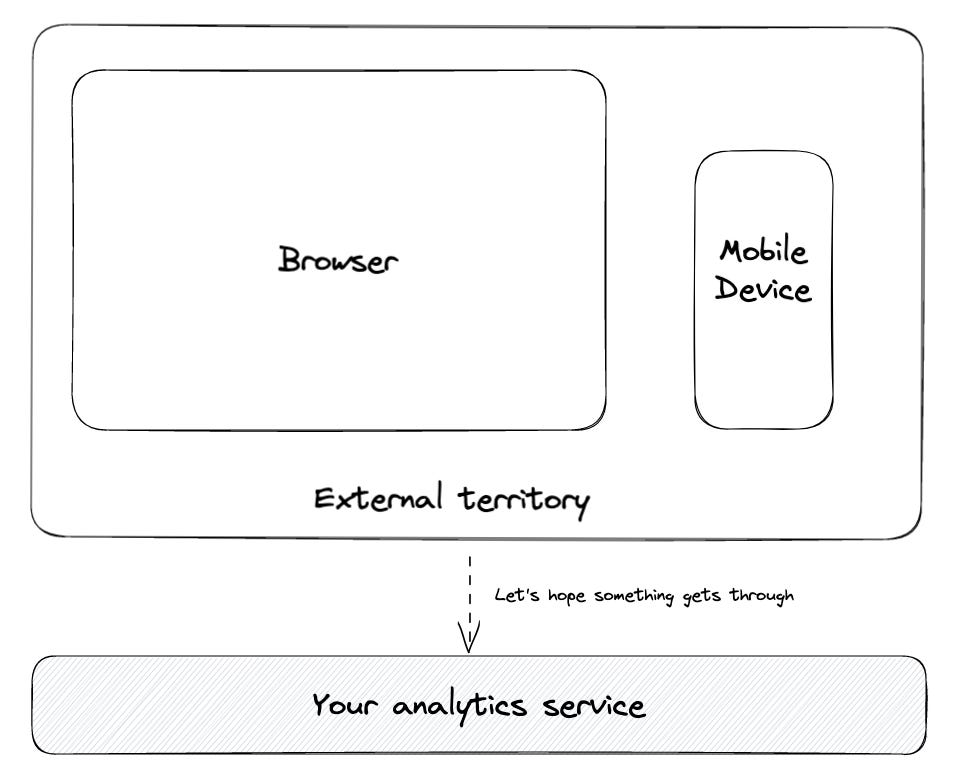
Let's keep one thing in mind - you need as much control over the pipeline as possible regarding data quality. If data quality is important, with frontend tracking, you have one essential part in your pipeline you don't control.
Take control in your environment.
Speaking about control. Server-side tracking runs on your servers. Or at least in an environment that you control.
Control is the essential difference. You don't rely on a third party to determine how the tracking events are triggered and if they can be delivered successfully.
You can also include the tracking calls in unit tests more quickly than in the front end.
But things are missing compared to the frontend tracking. As mentioned, frontend tracking gathers much information from the browser (like device type, IP address, screen size, and operating system). This context information can be helpful in specific analyses. This data is missing in server-side tracking, and you can only use the context your application provides.
And you need an identifier that you can provide with each server-side tracking event. This is usually the user id that is present for all application actions. You don't have a quick way to use anonymous identification, like in a browser or device.
But you can work in a hybrid approach where you track 1-2 events in the front end, use a user-id, and then follow the rest on the server side using the same user-id. By that, both pieces of information can be stitched together later.
How to implement a server-side tracking
Close to the API layer
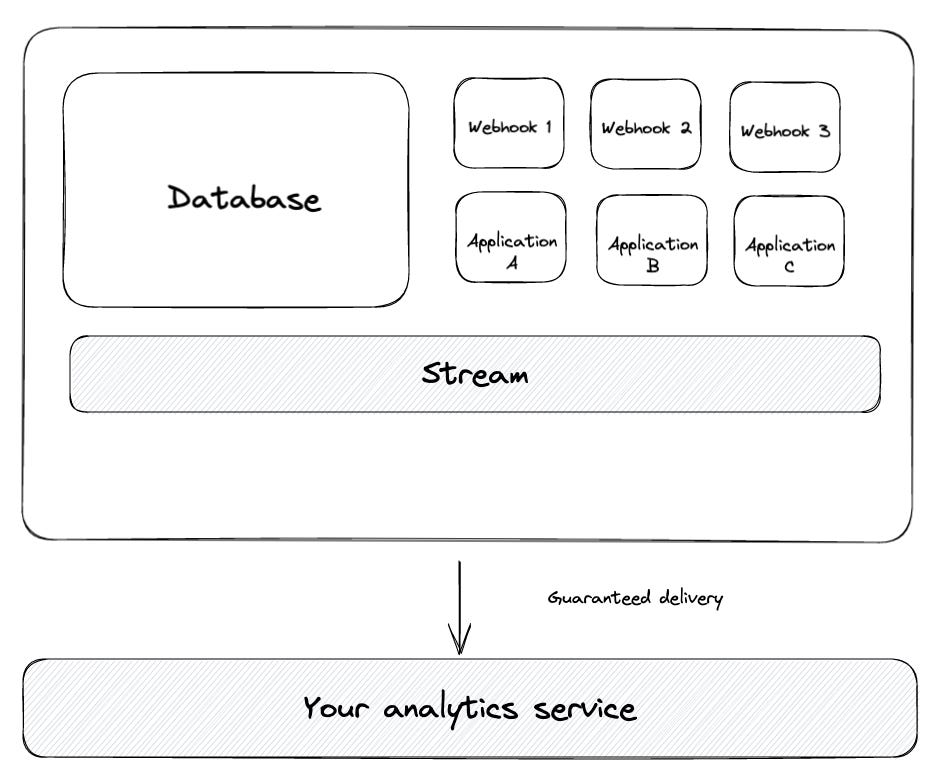
As described in my initial story, if you have a global API layer where most user actions trigger a call to this API, you can implement the tracking close to it.
The benefit of an API layer is that it already abstracts and provides most of the relevant information for tracking. Usually, all API requests require user information (usually by an auth token), which will then determine the user id. Then you can pull context information from the POST or PUT requests when things are created or updated. You can use the provided payload as tracking properties when someone requests information.
Close to the stream
Suppose you use a Kappa architecture and therefore have a streaming layer that will get events from application services and other application services that can pull and process them. In that case, you are as close as possible you can get to server-side tracking. In many cases, the tracking is another service subscribing to the stream. There might be some whitelist filtering to control which events you will pass on.
I did two projects where the team already used stream technology to publish and subscribe to events, and the initial tracking implementation was done in a short time.
One challenge can be the stream data itself. If the data is lean and uses ids heavily, you might need to enhance the application that handles the events with additional API or database requests to get all the context.
Close to the database
Similar to the stream approach. You can listen to database changes. This is one of the most common approaches; it is usually not called tracking at all. The technique you will use is called Change Data Capture, and different databases offer this out of the box. There are different types of CDC and different methods to ensure, for example, a transaction(outbox pattern).
As a different approach to CDC, some newer database systems offer webhooks (Supabase or Fauna). You can define a webhook triggered when a specific database operation has happened, and an application receives it and then sends it to the analytics system. This brings us to the subsequent implementation.
Close to third-party applications
Specific parts of an application are not handled within the application but by using third-party applications. The best example is Stripe, where you run all your subscription and payment processes. But these events are also essential for your analysis. In this case, you have two ways to get these events:
- via webhooks. A lot of third-party services are offering webhooks that are triggered by specific actions. You can build an endpoint to receive these events (sometimes, you already have that for your applications) and transform them into true tracking events.
- via batch load. Many third-party services have an API where you can pull the relevant application for you. From there, you sometimes get an immutable event log (Stripe offers this, for example) or snapshot data that enables you to derive events from that (a subscription has a created_at date, a last_renewal date,...). The batch load has the benefit that you are not responsible for ensuring 100% of receiving and delivering the events since you pull the result. But sometimes, the API data is not transferable in proper event data. Webhooks are events by nature.
Close to your application code
When none of the above methods are possible, you must add the tracking code where the action is handled in your application code. You might abstract this into a specific module or class to make it easier to update tracking metadata (or when you want to switch the analytics service).
This approach definitely works, but it requires more implementation and leads to very spread-out tracking and, therefore, can become a bit of a maintenance nightmare.

How to combine frontend and server-side tracking
In the end, not so complicated. The essential part is that both need the same identifier. When users are logged in, it is straightforward since you can use the user id in both environments.

The difficulties start when no user identification is possible, mainly on the front end. A popular example is a typical Saas flow. A user arrives with marketing source information (campaign URL parameters, referrer) and is recognized by a generated id that is then put into a cookie. All events are sent with this anonymous id. When this user signs up and gets a user id, the anonymous id and user id are sent together at least once. By this, they can be stitched together later. All product analytics tools do this automatically when you provide both ids.
If you don't want to generate an anonymous id in a cookie, you can also pass the relevant marketing information as URL parameters until a user signs up.
How do I implement tracking in 2023
If you can, on the server side. It makes the implementation, in most cases, easier and more robust.
But first, by involving the development team in the tracking data project from day one. They usually have a good sense of what implementation makes sense, and from my experience, they tend to implement it on the server side. And they know if the architecture on the server side is too complex for a simple server-side tracking implementation; therefore, a frontend implementation is more straightforward.
A hint at the end. If you, while reading here, thought about server-side tag manager as a server-side tracking solution. It's not. They share the name, but that's it. The server-side tag manager is just a tracking proxy that runs on your server, and tracking server-side is something completely different.

Solid write up. Anyone who has worked with product analytics or event tracking to any significant degree goes through a similar epiphany, in my experience.
It usually comes down to context vs consistency - client-side provides more context (IP, referrers, etc) and server-side provide more consistency (data integrity, events always firing, etc).
Pushing for server-side implementation for the events also helps with reducing the number of events, since it forces PMs/ biz/ whoever to identify the activities they care about. Usually it translates directly to engineering work, too, so there is a cost-benefit component to reducing the number of events to a more meaningful number. Also, it allows for "generic" events, where the fundamental event is the same - signed_up, for instance - but the mechanism through which it occurs can have many different flavors