


Ways to solve the data user identity & privacy crisis
Why we should think beyond using user ids for everything


Plenty of things made me fall in love with Kissmetrics when it came out - but one feature made it irresistible for me: The user explorer.
The Wayback Machine is great when looking for some old feature descriptions. https://web.archive.org/web/20140228094856/https://www.kissmetrics.com/features
In an aggregated world of analytics data, this report looked weird since it showed event sequences on a user level. But for me, it was like a treasure chest. I picked specific segments - like the ones who dropped off at a particular step of the funnel and then checked 20-30 individual user explorer profiles. And I could find patterns and ideas for deeper investigations just by the sequence of events and user properties.
That made me also fall in love with the user id, which was required for good user explorer reports. So I still prefer setups where I can get a user id when users have to log in.
But data privacy is challenging this concept. So, do we always need a strong identifier like a user id, or can other approaches also work? Let's investigate this.
Identifying a user as a global proxy
Why do we try to identify a "user" at all?
To get these event sequences by one person because we hope the sequence can tell us more than all the isolated events alone. We get to the sequence in a second. But let's look at the different ways to identify a "user"“ And yes, there is a reason why I use ""“around a "user."
Ways to identify a user
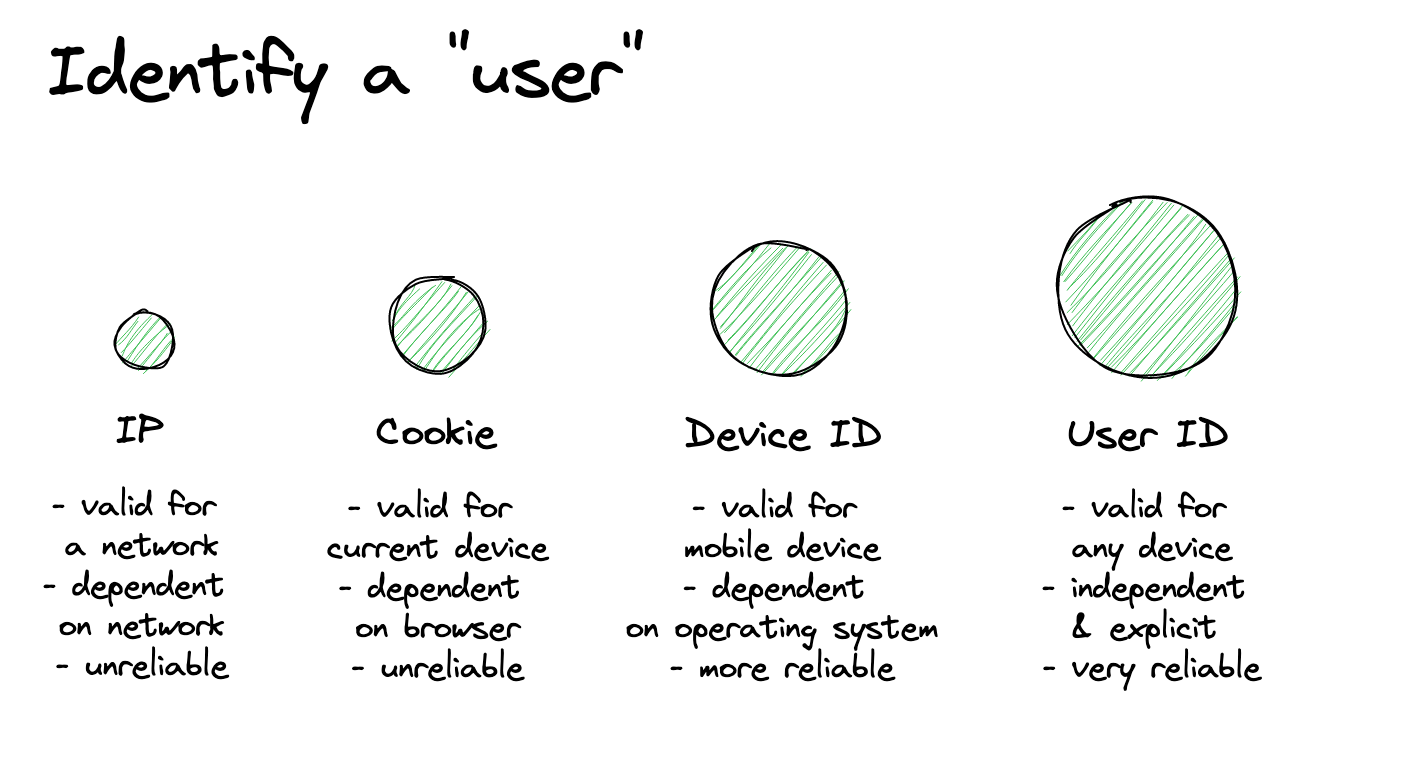
By IP-Address
In log file analysis, the IP was the identifier. We could analyze a sequence of HTTP requests for one IP-Adress to see how one "user" is browsing a website. But how unique is an IP address - well, it has limits. If you have multiple people in your local network, you can appear with the same public IP address (at least what my 10m of internet research told me). And IP-addresses are usually dynamic, so they change within a day or two. So a short sequence within an hour is pretty likely unique but not a user journey that spans over days or weeks.
By cookie value
When we got the first Javascript trackers, we got a session, client, or user ids saved in a cookie. The setup is simple. A person opens a website, the script checks if there is an id in the cookie; if yes, it uses this one for its tracking; or no, it creates a new one and saves it in the cookie. Pretty simple.
How unique is it? If the user stays on the same device and does not delete the cookies pretty consistent and unique. In the early days of the internet not a huge problem. But with mobile phones and multi-platform, significantly more of a problem. And with tracking consent even more, every identifier saved in a cookie or local storage potentially needs positive consent.
By device id
With mobile phones, we got something more persistent than cookies - the device id. This can be an idea the operating system provides, like the IDFV, or a generated id stored on the device.
How unique is it? For a mobile device is pretty unique. Suppose the tracking uses an operating system identifier like the IDFV (and you don't offer multiple apps - the IDFV is similar for each app by one developer and the user's device). In that case, you don't even set a unique identifier. But it might still be something you can only use if you have the user's consent (https://mobiledevmemo.com/french-privacy-watchdog-to-voodoo-games-use-of-the-idfv-requires-consent/)
By login and user-id
When a user signs into an application, the backend system usually returns a unique user-id for this account. This makes it possible to track users across multiple devices and platforms.
How unique is it? As unique as it gets. Since the users proactively identify themselves in the application, you can be sure that this user is really a user. Does this need user consent? Yes, at least something you should check with your legal advisors.
Why do we want to identify a user?
We don't need any identifier if we are interested in how many signups we have or how many new tasks have been created. The event count itself is sufficient.
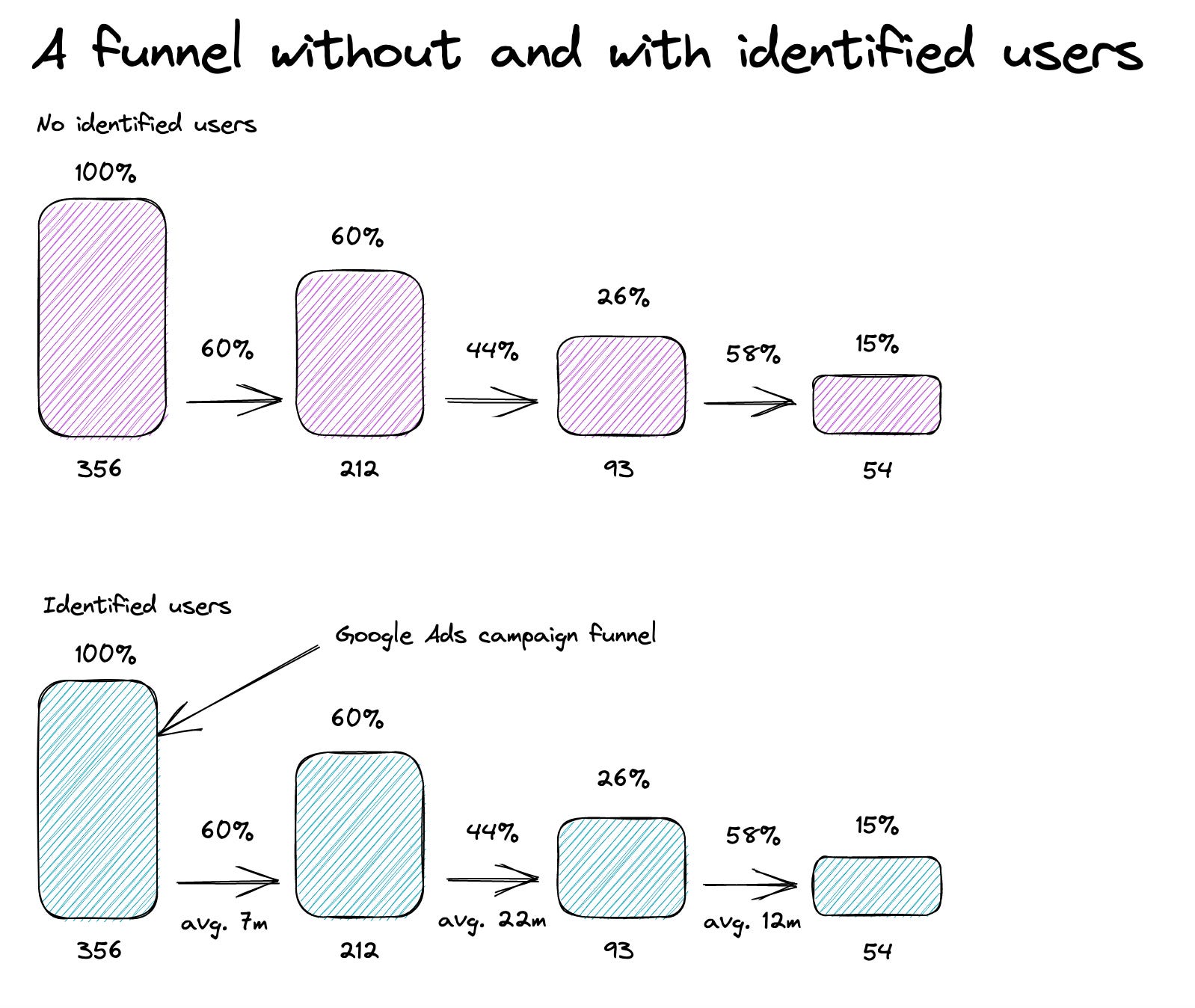
We need an identifier when:
- we want to see if users are getting to the point where they get value from our application. This will always be some funnel - like account created -> website published
- we want to see if our application sticks with our users. Suppose they come back over days, weeks, and months. Classic retention analysis works with consistent unique identifiers (like user ids).
These two use cases are the core cases for any product analytics work. Is product analytics then even possible without a unique user id? We get to this in a second.
Let's look at marketing analytics.
If we want to analyze a classic e-commerce funnel, we could do it without an identifier, assuming the usual buyer's journey happens in 30-60m. We could look at the number of events for each step - from cart to order. Problematic are events that are happening multiple times per user - like product views.
We need an identifier to know which initial marketing campaign led to an order. The information about the traffic source is usually only present with the first event/pageview, and an identifier allows us to apply the traffic source to all the following events.
So we need identifiers to do more advanced marketing analytics.
But let's ask the obvious question? Do we need a user identifier?
The user proxy
We use the concept of a user (ip, cookie, or user id) mainly because it was at hand when we were starting. And because it was as granular as possible, many different types of analysis could be just derived from it.
The user identifier is a catch-all approach.
When we can track a unique user identifier, we can build anything from it since it is the most individual and granular identifier possible.
I am not legal, so I will not examine this from a legal standpoint.
But let's look at it from a simple privacy-by-design perspective.
When I collect data in the way I need it for my analysis, I don't default to the identifier with the most privacy impact, the user id. Instead, I look at what kind of aggregated identifier is sufficient for the analysis.
What are different aggregated identifiers?
Let's develop different identifiers.
Identifiers that are on an aggregated level and see what we can do with them.
Account or Team ID
What is the difference between an account and a user id? In an application where one user = one account no difference at all. But we have an interesting new identifier in a typical B2B application where an account can have plenty of users or even different teams.
In a B2B Saas use case, we are even more interested in account performance than single-user performance. Because the account performance, in general, tells us if this account might convert to a subscription (which is on the account level) or if it is likely to churn. If we need more details about the different types of users in an account, we can introduce a role property that extends the data by tracking which role in this account has triggered the event. When we have huge accounts (meaning 100+ users in an account), it can make sense to break it down to teams if this is a feature in the application.
Limitations: An account-based identifier comes close to a user identifier when we are in a B2B application with accounts and multiple users in that account. Using a user ID identifier is problematic in these scenarios since the account dimension is missing. Classic product analytics tools like Amplitude or Mixpanel usually track this with the group identity feature.
User group ID
This is a variation of the account id approach for cases with no account level, and you basically group users based on different criteria.
At deepskydata, we ask members, when they sign up, about their experience level, job title (from a list), and where they heard about us. We can combine these criteria into one id based on every permutation. By that, we choose an aggregation level that will be broad enough for privacy but close enough to analyze correctly.
Limitations: A classic problem of aggregated identifiers is that avg. The time between funnel steps can be off since it lacks individual and granular data. One way to solve it is to extend the group criteria with the signup date, and this will also enable a proper retention analysis.
Content ID
Let's assume you have a content website. With 100-1000 different content assets, you are primarily interested in individual content performance. Here we can use the content id as an identifier to track core content usage events.
Limitations: The time between funnel steps will be missing. Same for content retention.
Campaign ID
Let's assume you have a marketing website for a product. You are primarily interested in how a specific campaign performs on the customer journey. Therefore you can use the campaign id as an identifier and track all customer journey events. This gives you a proper customer journey funnel broken down by the different campaigns.
Limitations: Same as for the content id. Avg. time between funnel steps and retention analysis is missing.
The account and user group id are good examples of choosing an aggregation level of users. Still, they can do everything we usually do in product analytics (funnels and cohorts).
The content or campaign id is a good example where we choose a different entity we focus on and use it as an identifier because we are foremost interested in the performance of the content or the campaign and don't care about the individual user.
I am currently writing my first workbook: : How to fix tracking.
Preorder it now for just 35 USD.
How to track different identifiers?
All good product analytics products have a group feature for the account id approach. But be careful. In most of them, it is a paid add-on, so ask for the price. In cloud-warehouse native tools like Kubit, the account is just a different schema you can use for analysis.
If you use the aggregated user id or something like the content id, you need to use the user id property for this. You can use any value as a user id in a product analytics tool, usually done in an identify call.
If you want to make sure to respect the user privacy and don't do any user-level tracking, you need to make sure that you:
- disable cookie tracking (check the docs, for most of the tools, it is possible, but not for all of them)
- provide the user id with each event call
You can even go further when using Snowplow for event tracking.
Snowplow has the concept of custom contexts, and you define which context is relevant for an event and provide it accordingly.
So for a "content read" event, you can have an account context (if a user is logged into an account), content context (with content name, id,...), consent context (for what the data can be used), experiment context (which test variant is visible). But the user tracking itself is set to be anonymous and therefore doesn't generate any user-level data.
On my list is to experiment more with the aggregated user-id approach to introduce a level of user data that respects the individual but still is powerful enough for funnel and retention analysis.

"how to use this content disclaimer."
After I wrote about taking every bit of data content with the correct grain of salt, I used a disclaimer under each post to indicate how to use it.
Some concepts in this post are theoretical (the aggregated user id). I have implemented some ideas successfully (account id pretty often, content id, and campaign id in one project each).