


What is beyond event data?
When Data Events are iron, Activities are your steel-building parts.

Activities are the missing business layer for your event data.

Yes, there was a time when digital analytics data was just pageviews, and it was fine since each click caused a new page loading— a simple and straightforward system. But we moved on. Websites to use asynchronous requests (so no page loads after clicks), mobile apps with in-app interactions, backend processes with emitting events, streaming queues, and webhooks. Not so simple and straightforward anymore.
My analytics Eureka moment was when I discovered tracking events with Kissmetrics. It was before Google Analytics introduced them. And I was immediately hooked. Defining explicit events when something explicit has happened was simple again. Someone submits a form, and I send an event “Form submitted.”
Events became my first-class citizen in all my tracking setups. Pageviews became secondary. And with the new breed of analytics products like Amplitude, Mixpanel, or Segment, custom events became the standard.
I call them custom events here since events in the old (now sunsetted) Google Analytics or in Piwik Pro have a fixed structure of what kind of context information I can send with them. A proper event for me has no limitations.
What is an event in data?
As just pointed out, even in analytics, there are different forms of an event. So let’s dissect this a little bit so we have a shared understanding of which is important for the next steps.
In its simplest form, an event has:

A timestamp
A unique identifier
The timestamp is essential since event data enables us to understand sequences of actions from users or systems. We need a timestamp to bring this all in the right order. The timestamp itself can become complex, but this is a different topic for a separate post (as a teaser: a client timestamp and a server timestamp are different - and if we analyze micro sequences, milliseconds matter)
The identifier is often a programmatically generated unique id. Unique is essential to handle potential deduplication.
In this form, the events are not telling anything. They are technically valid but missing at least one thing for analytical purposes: a meaning.
Give an event a meaning.
So let’s extend it:

A name
Please keep the concept of meaning in the back of your head; this will play an essential role in what will come next.
We give an event a name. With this name, we try to describe what kind of action triggered this event as best as possible. There are famous blog posts on how to name events, and I even currently write a book about it (it’s a complete chapter about it).
The reason is that we are now leaving the pure technical space we had before and entering the area of human mess, which is language.
There are books written about the mess language creates. But we can also do it in a simple version. We have an event and named it “Newsletter subscribed.” Now we get around and ask people what this means. And we ask beyond the obvious, “Well, someone subscribed to a newsletter.” Did they submit the signup form? Have they been added to our CRM? Have they done the double opt-in?
It’s quite impossible to name an event that would answer all these context questions. Maybe “Newsletter double opt-in saved” would be technically more precise. But have fun letting business teams work with that. We pick this problem up in the next paragraph.
Adding event context
One way to make the meaning more precise is to add context. And we do usually do that by defining key-value pairs that we add to the event data.
So our “Newsletter subscribed” event could be extended like this:

These event properties help us better understand the event's context and meaning and give us additional dimensions to analyze event data (here, we could generate a chart that breaks down subscriptions by topic).
In most analytics systems, an event looks like this.
You can see a user id often attached to group events to a specific identifier. This identifier concept can also be even more complex, but in the end, we add ids that we use to join more context later during analysis.

The problems with event data
We already discover a glitch in our event data setup in our definition—the meaning of an event. Most problems I discover when working with a client on an event data setup are based on this. The other problems are technically around the event collection.
Let me give you my list of event data meaning problems:
Duplicate events

You want to analyze the impact of newsletter subscriptions and the discount users get on your orders. So you check your current setup to find proper events that would allow you to build a cohort of subscribed users who got the discount.
You find these events:
“Newsletter clicked”
“Newsletter start”
“Discount added”
Now you are still determining which would help you work with it. The docs need to be updated; no one can tell you which one to pick. And the developers tried to find where these are triggered, but you get mixed feedback.
This analysis is important since you will initiate revenue-relevant activities based on this. So you must be 100% sure that the events you use are triggered for the right context.
So you ask the developers to add a new event, “Newsletter subscription Discount added.” Your analysis is safe now, but you decreased the quality of the event data setup because technically, “Discount added” had a property “cd” which holds the discount code and is triggered when a discount is applied to the cart. Now you track the same thing two times.
Too many defined events

The scenario above led to too many events. But there are more reasons.
The “be on the safe side approach” is also causing the issue. You are unsure what kind of event data would be needed for analysis. Or you want to do a proper job and show people you took the setup seriously.
This always ends up in a high number of unique event names. And the high number starts for me at 50.
This approach gives you great event names like these:
Layover top box close button clicked
Navigation second layer item clicked
and these are still good examples. I saw far worse ones, and I guess you too.
And concerning meaning: More events don’t make meaning easier; it usually makes it more complicated.
Hey, I’m from Data. I speak a different language.
Take a concept like revenue and ask all teams in your company how they would define it, and you will have X different definitions. All right in their context, but still different.
When I work with data teams to design event data, I always recommend taking their first version of names and talking to plenty of teams about how they understand it and if a different name might be better. This usually improves understanding.
But the knowledge of details can still be a problem. For a product team, “Task comment added” can be understandable, but for a sales team, it is too far away from their daily work (what does this mean for me).
Enter the world of event data abundance.
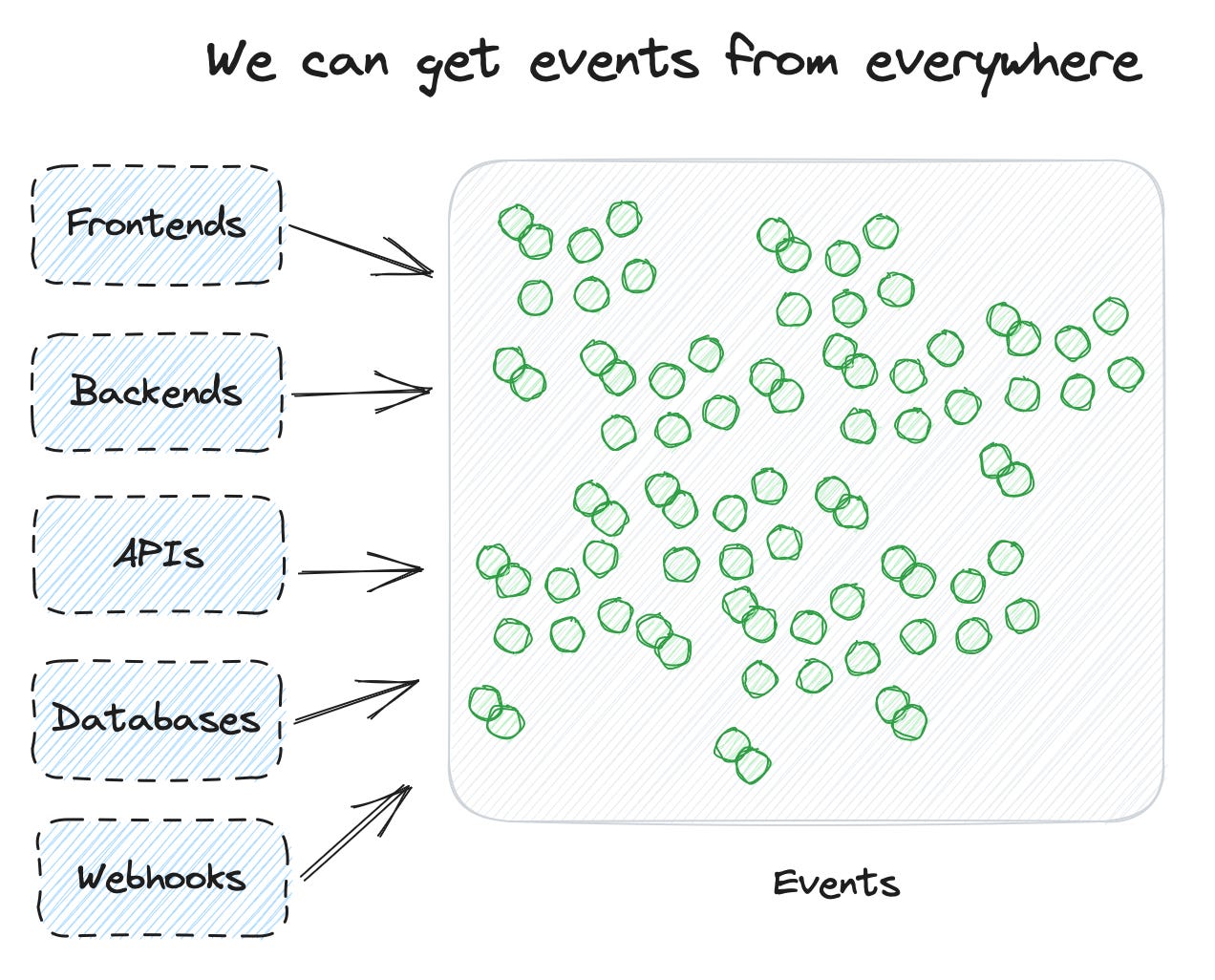
When I started with event data, we explicitly added them to our front-end application. So one place where they were collected.
At some point, we started to send some events from backend processes. Either it increased the quality, or the action was solely happening in a backend process.

Then we thought plenty of core actions were based on database interactions, so why not use this data? There is this concept of CDC (Change data capture). We can use these logs to derive events. If a new record is added to the member’s table, this is equivalent to a “member created” event. Implementation and quality can be pretty good with that.
Then we wanted to know what happens in the third-party tools we use. Well, they offer an army of webhooks, so why not receive them and add them as events?
Our development team has started to use streams to trigger different software processes. We can subscribe to them and select meaningful events for analysis.
Now we can easily have 1000 unique events available. And some of them could be for a similar thing but at a different point of the sequence:
Newsletter form button clicked
Newsletter form submitted
Newsletter record saved in DB
Record synced to CRM
Created in CRM
If we added all these just into an analytics system, we would kill any usability.
This final problem was the tipping point for me to think about a different way to handle this.
A new layer to bring meaning: Activities

Adding a new layer is something familiar and happens quite usually. Just have a look at software engineering. We don't write assembler code anymore; we added layers on top of it. Many layers, to be precise.
The same happens in data as well. dbt is, in the end, a layer on top of the native SQL engine of a database. And Tableau is another layer on top of it.
A concept that has started to get more traction again is the semantic layer or, more precisely, the metrics layer part of it. The metrics layer is not a new concept but receives a new interpretation now.
One core function of a semantic layer is to serve as a translation layer between business requirements and data availabilities. In the case of the metrics layer, you define a metric by name and how it should be calculated (and formatted), and then you define which data should be used to calculate it. It is a bridge document. It frees up the business to know anything about the database source and helps data understand what metrics the analysts need to do their work.
David wrote an extensive 5-part series about the semantic layer, which I highly recommend reading:
What if we introduce a part of the semantic layer: the activity layer
This is also familiar. Ahmed is doing this with his Activity Schema approach, and they have an activity layer natively in Narrator.
But you see it only sometimes in public posts, which is also because even events are secondary items in most data models. But this is a topic for a future post.
So, let's have a look. What would an activity layer look like?
The activity layer - a first draft
Ultimately, we want to achieve something similar to what the metrics layer does, bridging the data with the business requirements. But here, we don't map database table columns to metrics, but we map events to activities.

In this setup, activity is an event on a business level. Mmh, this is still too abstract.
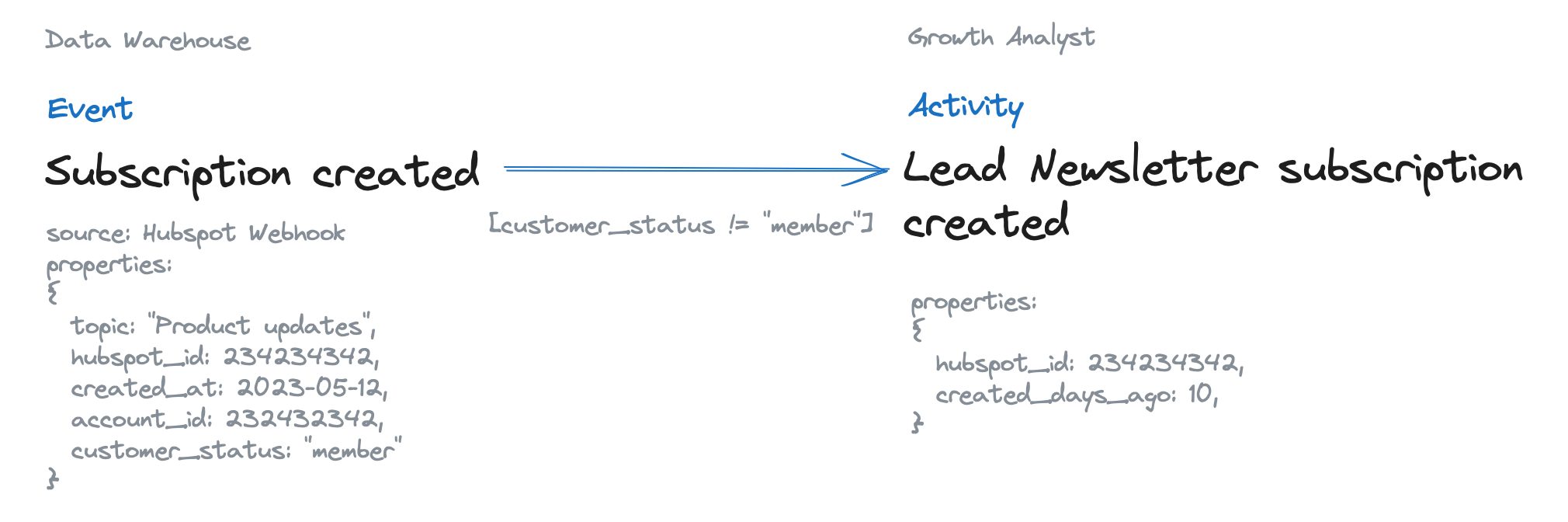
Let's retake our example. An activity could be "Newsletter subscription created." This is an activity that is important for the growth team. We now have different technical events where we can decide which defines this activity. We choose the webhook event "Subscription created" from our CRM. This mapping gets into our activity layer definition (we get to that in a second); therefore, it is easy to check for everyone if you want to know where the data for this event is coming from.
We could change the CRM vendor; we could move it in-house. The activity will always stay the same, but we change the mapping underneath (versioned). So people can keep the analysis and report based on it the same.
This is a direct mapping example, but we can do more complex examples.
Using filters
Maybe we want to create a "Lead newsletter subscription" (we could also handle this with a property - but this is important for us). We then can use a filter on the primary event from the CRM that makes sure we only map the events from users who still need to be customers. Again, all in the same central place, visible to everyone.
Using sequences
We can even use sequences of events for the definition of one activity. Something we already know from product analytics tools like Amplitude or Mixpanel. Let's take an activity, "First value generated," which can combine different events indicating that users got their first value from a product.

Coalesce event data
Or we coalesce event data. So when we have two sources for a similar event, both tend to track only some of them. We can define a coalesce to use event source A if present, and if not, use source B (as long as we have a shared identifier).
Refactor events
This new layer also finally helps us to refactor event data setups. You can reduce unique events, merge events, rename events, and improve their definition and quality over time.
Ultimately, the activity layer decouples the old paradigm: event instrumentation = event analysis.
How to implement an activity layer
Most likely, this will be part of your data model. You add queries that work on your raw data and define the activity. In a dbt setup, that would be a folder serving as the activity layer where you work, e.g., with the raw event data you get from Snowplow, Segment, or Rudderstack.
So far, I have used the ActivitySchema concept (in a slightly different form than proposed in the v2 schema). This works great for me.
I still think about a real layer approach where the activity layer is a configuration (YAML or JSON) that translates to SQL. We can also work in batch mode compared to most metrics layer implementations that do this for ad-hoc queries. But a configuration would also enable streaming use cases.
Final thoughts and why I think this important
We move to a new stage of event data. Event data before was often directly connected to an analytics solution. This is breaking up. Only slowly but steadily.
And we see more data use cases for event data.
We can now work with Data Warehouse event data in product analytics tools. Natively with Kubit or synced with Amplitude and Mixpanel.
We can run a full-fledged experimentation stack on top of our DWH event data with Eppo.
You can sync the event data to Customer.io or Vero from your DWH.
You send modeled activities as different conversions events to ad platforms like Google Ads
You can qualify leads based on DWH activities in Correlated and create sales tasks.
And more and more products are coming built on top of the DWH data.
We need an additional layer to abstract raw technical events from business activities.
Please let me know what your thoughts are. Does this make sense, or is it too abstract or too early?

Great read. Thanks for this!
Hi Timo! How can I explain in a simple way that implementing events in a mobile app (logevents) is different and easier than implementing events in a website via DL. This in terms of web analytics - GA4.